降低精神内耗的服务运行环境搭建
内耗
好久没有写字了,实在太懒,尤其是最近遇到的事情太多,我也好像陷入了“内耗”。
精神内耗,又叫心理内耗,它是指人在自我控制中需要消耗心理资源,当资源不足时,人就处于一种所谓内耗的状态,内耗的长期存在就会让人感到疲惫(这是我从百科上抄来的)。“精神内耗”这个词可能是从前阵子“二舅”那里火起来的吧,别管二舅最后怎么样了,精神内耗终于还是和“熵”类似,是一个令人很沮丧的东西,所以降低精神内耗,在一个积极的生命背景下,还是非常有必要的。
算上一次,我已经把我的blog搬空了三次了。其实也不是真的丢了,只是我懒得去恢复,实在也没有什么太多东西。唯一有些意义的是记录的一篇docker swarm建站相关的内容。在用ghost重开blog的第一篇,我准备写一些和它关联性很大的内容,关于如何创建一个完整可用的,适合于个人和中小团队的真实线上服务运行依赖环境的说明为主的东西。我是希望它可以真正降低环境理解和日常维护的心理负担的,也就是,它真的可以降低精神内耗。
Kubernetes生态很好,istio很好,各种云原生都很好,但是它们也真的是消耗(这里指的当然不是服务器资源)不低,首先需要确认的是,个人开发者和中小型团队是不是从一开始就玩得动它们,对于一个项目的开发和验证期,还是应该把精力更多地投入在业务和体验本身,而不是为数并不多的硬件资源和访问量上。当然,我们也没必要按照20多年前ftp+虚拟主机空间的原始方式去部署应用,该有的自动化过程和必要保障,还是不能少的。在这样的情况下,我还是更倾向于如今时代已经没啥人再去提及却好像又到处都在的docker swarm体系,虽然它一点也不潮,过于简单,但是它也是真省心。
以下实例,基于最新版本的Docker,关于Docker Swarm,其实没啥可说的,甚至我们也可以很容易地用一些k8s的轻型实现,如microk8s、k0s等来替换掉它,所不同的也许只是描述文件的格式而已。
我们会在实例中实现
- 一个基本的服务治理环境
- Traefik网关
- Prometheus metrics
- Grafana
- 日志收集及管理
- 基础设施监控及报警
- 简单的CI流程
- 服务版本化
我们的实例中包含的资产(腾讯云)
- 六台虚拟服务器,其中三台轻应用服务器,三台CVM,均在同一个可用区。
- 三个独立的标准云盘块,一个轻服务器的云盘块。
- 一个很小的MySQL实例。
(快双11了,大家有资产需要的可以准备下手了)
不知道大家手里都有一些什么设施呢?如果只是想做个实验,virtualbox几个虚拟机也是可以的yo~
首先,开机
创建好对应的虚拟网络,初始化服务器。我选择了对我来说,内耗相对小的debian,大家喜欢什么自己干就是。

各家的“轻应用服务器”(LightingHouse)其实是使用了更轻量但是资源共享程度更高的虚拟化技术隔离出来的“重容器”,相比传统的虚拟服务器,成本更低,但是可能跑不到那么高的理论性能。不管是阿里云还是腾讯云,轻应用服务器卖得都更便宜,可选配置少一些,限制也会多一些。不过,通常都会在低价范围里拥有更大的双向带宽。
所以,这里我会做一些特别的设定,我用三台轻应用服务器来做对外的网关入口,环境依赖,日志,然后用CVM来跑实际业务应用。也就是说,在我们这样一个小集群里,混合了两种规格的虚拟节点。然而,腾讯云的轻应用服务器和标准CVM的虚拟网络是并不联通的,所以,下一步,我们要做:
联网
如果你的资产已经都是互联的,或者是在做单机环境,可以不用特别关注这一块的联通问题了。
下面是我的虚拟网络,在腾讯云华东:
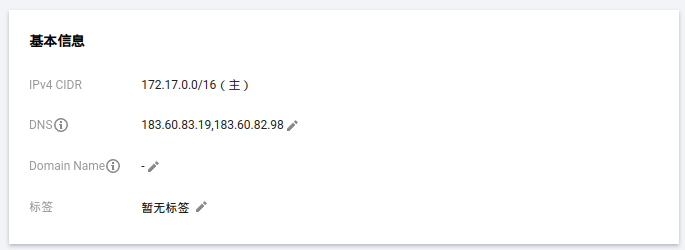
这里发生了一个让人有点纠结的事情,这个虚拟网络的内网IP段是172.17.0.0/16,它会和docker的默认网络设备docker0冲突,所以后面在处理docker环境时候,我们要特别注意这里。
下面有一个子网,在上海五区,上面的三台CVM都在这里了:
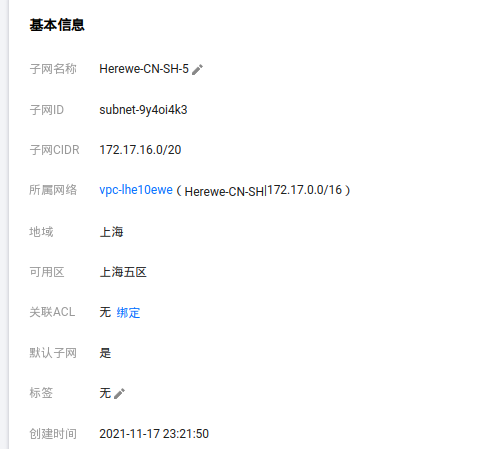
这里子网,只能关联CVM,而我的另外三台轻应用服务器在它们自己的子网里,互相是不关联的。需要使用腾讯云的云联网将两张子网连起来,这个功能,在同帐号同地域下是免费的。[文档]
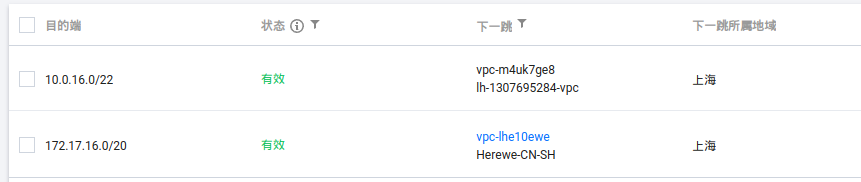
这样,这六台设备就内网联通了,下面是我的内网IP:
我是内网IP
- 10.0.16.10 herewe-q01(我们是轻应用服务器)
- 10.0.16.16 herewe-q02
- 10.0.16.17 herewe-q03
- 172.17.16.14 herewe-c01(我们是CVM)
- 172.17.16.16 herewe-c02
- 172.17.16.17 herewe-c03
让我来互ping一下试试:
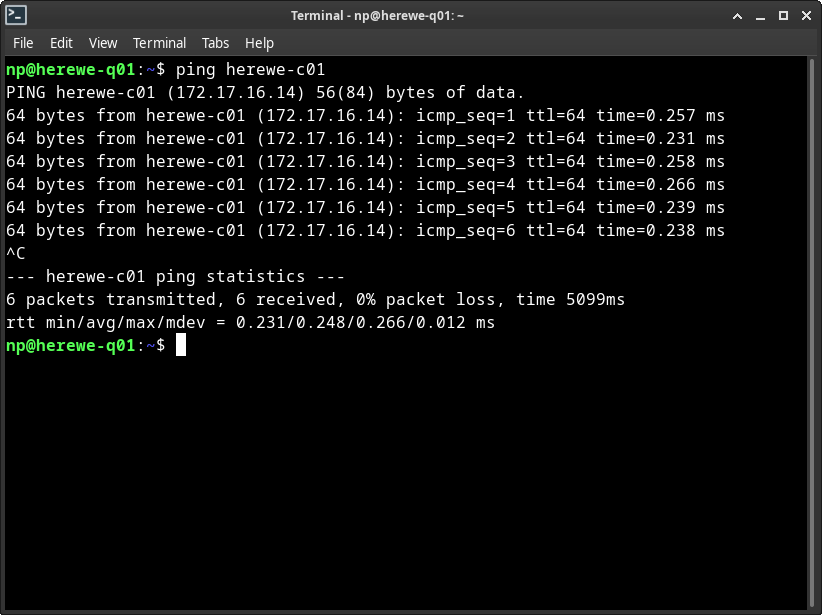
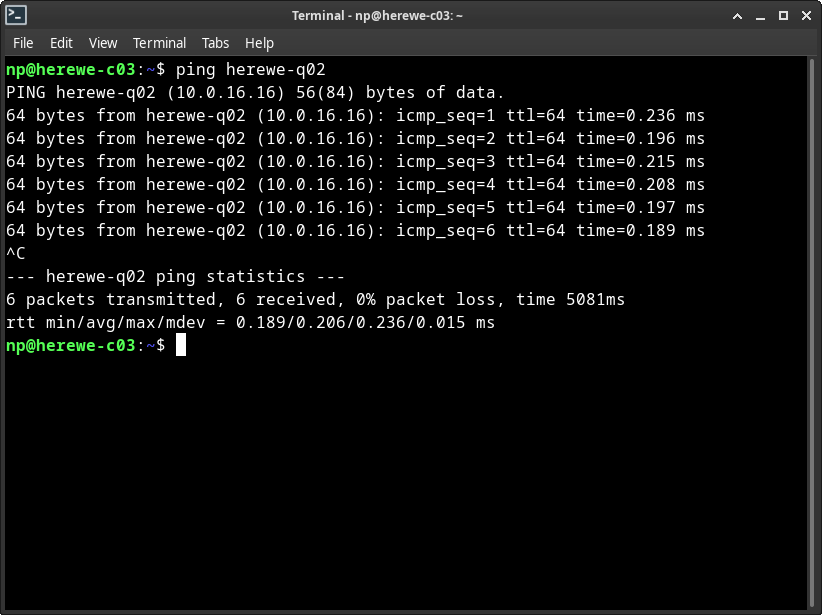
双向畅通,不赖。下面,我们来做我们的第一件工程:
Docker Swarm
首先,以正常的姿势安装好docker,我们这里用官方的debian源,参考[文档]。
插曲:前面我们已经说过了,CVM所在的虚拟网络的IP段好巧不巧地是172.17.0.0/16,这个时候就会和docker0发生冲突,导致docker节点间通讯异常,所以我们把docker服务处理一下。编辑/etc/docker/daemon.json,添加:
{
"bip": "172.26.0.1/16",
"default-address-pools": [
{
"base": "172.27.0.1/16",
"size": 24
}
]
}
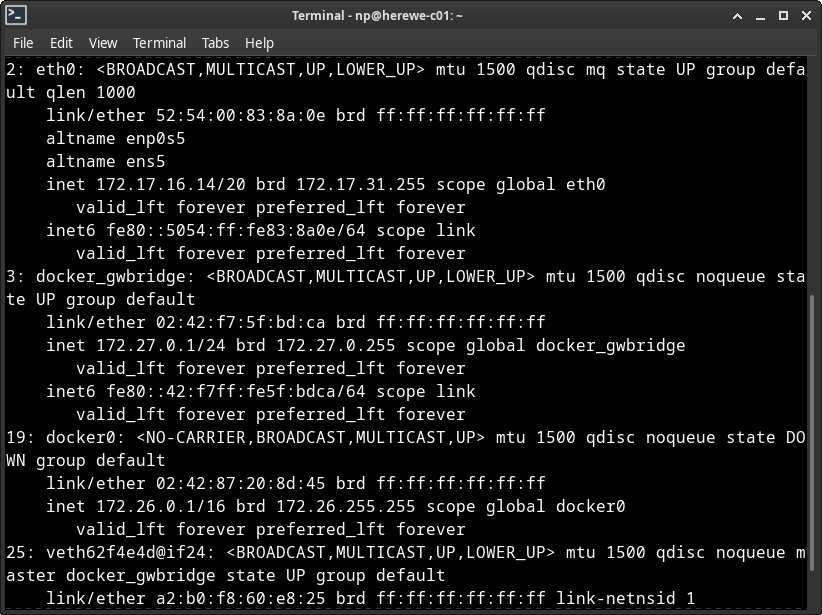
然后重启docker服务,就会发现网络设备中的docker_gwbridge(用于节点间通讯)的地址变成了172.27.0.1,docker0变成了172.26.0.1,很听话的样子:
然后,我们来创建swarm集群。docker包含两种节点,分别是manager和worker。manager负责管理集群间的通讯,资源和容器调度等,worker用来运行容器。manager可以是多个,会使用投票算法选主[参考],所以通常manager节点数都是单数,且一般不会超过7个,而worker不受限制,之前看到过有2000个worker节点的swarm集群很正常地跑着。
Manager节点并不单纯只进行集群管理,它也和worker一样可以运行容器,因为管理动作是很轻的,并不会占用多少资源。
这里,我让三台轻应用服务器来做manager,三台CVM来做worker。
在q01上执行:
docker swarm init
就创建了一个swarm集群。如果q01的默认网络设备有多个地址,需要用--advertise-addr来指定一个,这个地址用于其它的节点的加入。创建成功后,会返回两个token,分别用于manager和worker节点的加入。忘了没关系,可以用
docker swarm join-token
来查看。然后在q02和q03上执行:
docker swarm join --token {MANAGER的TOKEN} 10.0.16.17:2377
q02和q03就以另外两个manager的身份加入了集群。然后在c01、c02、c03上执行:
docker swarm join --token {WORKER的TOKEN} 10.0.16.17:2377
c01、c02、c03就以worker的身份加入了集群。这时候,在q01、q02、q03任意一台上执行:
docker node ls
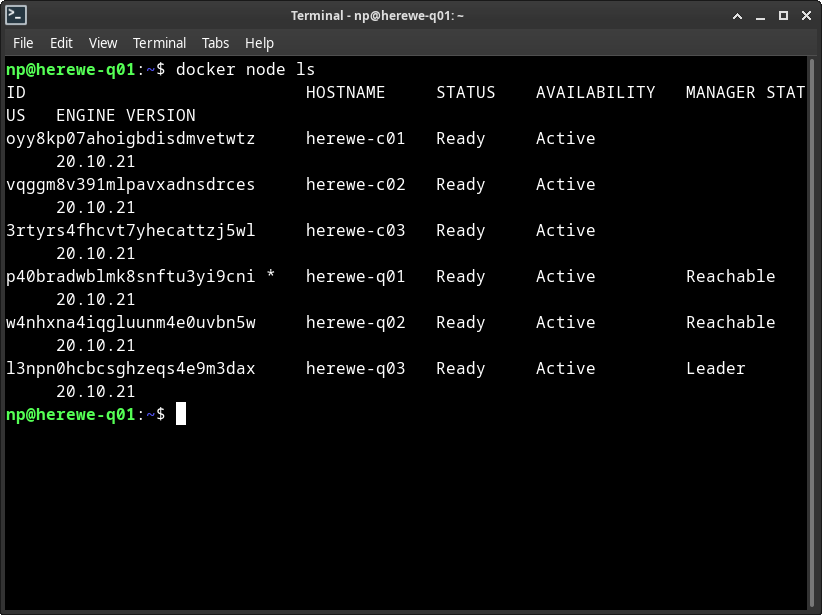
列出了当前集群中所有的节点(这个命令只能在manager上执行)。可以看到,当前集群中有三个manager,当前被选举的leader是q03。如果q03发生了异常,swarm会选择一个新的manager出来做leader。
插播:如果你的服务器上有防火墙规则,在内网范围内需要开放:
- TCP 2377端口,用于节点管理
- TCP / UDP 7946端口,用于节点间通讯
- UDP 4789端口,用于overlay网络
上面提到的overlay网络,就类似于k8s中的cni模型,用于连接容器,让所有节点上的容器在一个虚拟的网络上互相可访问。下面,我们创建一个overlay网络。在manager上执行:
docker network create --driver overlay --attachable herewe-net
就创建了一个名字叫做herewe-net的overlay网络。这个网络会覆盖整个swarm集群:
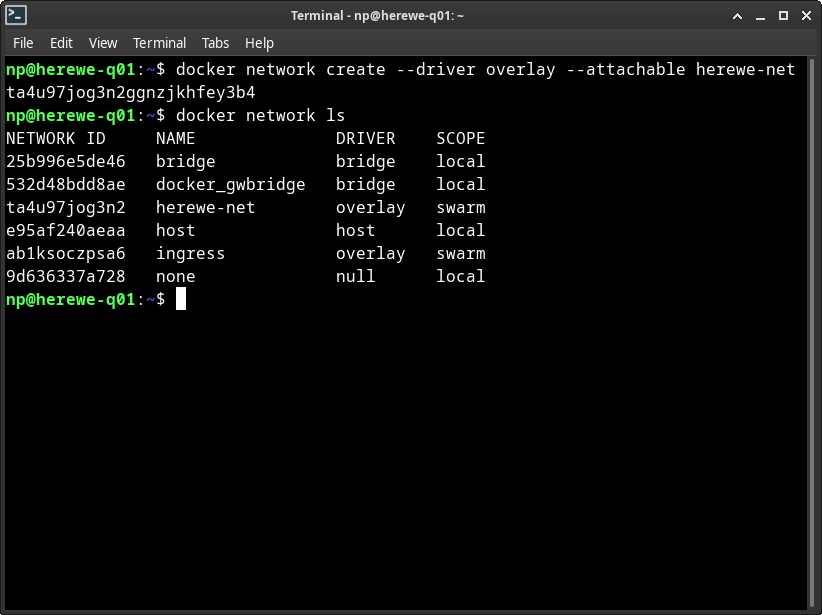
在network ls中可以看到刚刚创建的herewe-net,范围是swarm,这时候,在其它manager节点上也看得到它,在worker上看不到。后面,我们所有的容器都会依赖在这个网络上来运行。
至此,我们就创建了一个可以真正使用的swarm集群,是不是很简单呢,它相比k8s的部署,对于普通开发人员的精神内耗要小得太多了。
共享存储
由于我要在六台节点上起容器,swarm会根据资源自动调配容器的启动位置(replicated),然而,容器会有一些mount volumes,不管是内容存储,还是配置文件,这些内容需要在节点间共享。这里有很多种方案来实现,比如我们自己搭建nfs,glusterfs等,或者借用云服务提供的存储。这里我在低精神内耗的需求前提下,直接在腾讯云上开了一块CFS,并挂在所有节点上的/data/shared上:
在/etc/hosts中添加一个alias:herewe-shared-cfs,指向存储的ip,然后编辑节点的/etc/fstab:
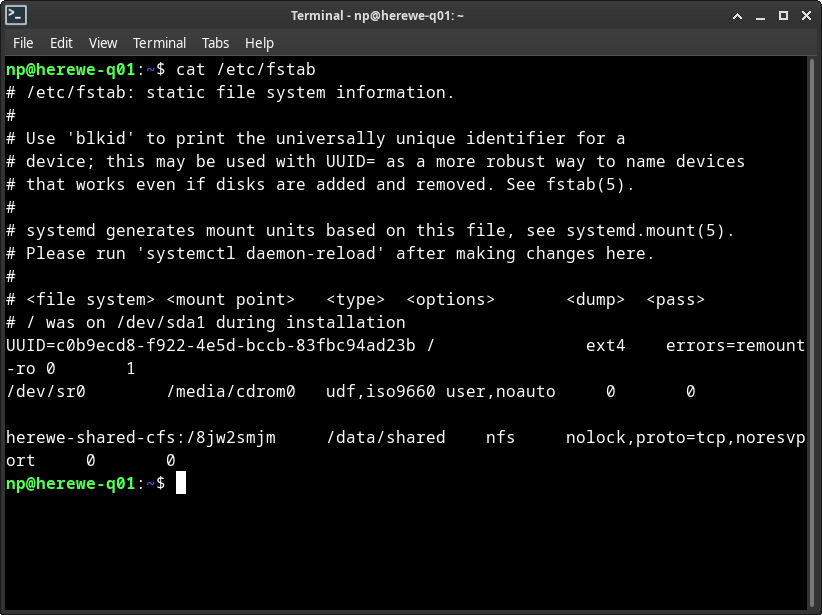
创建对应的本地目录/data/shared,然后在所有节点上执行:
sudo mount -a
这时,可以在节点上看到了新的挂载内容:
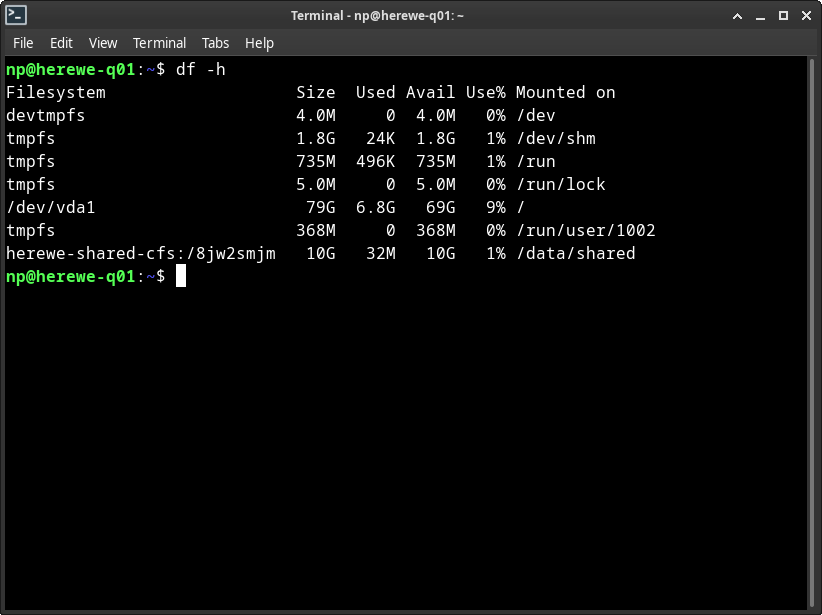
初始化的32MB内容,是元信息,这块是不计费的,不用担心。我们在其中一个节点上创建一些内容,看看在其它节点上能不能读到:
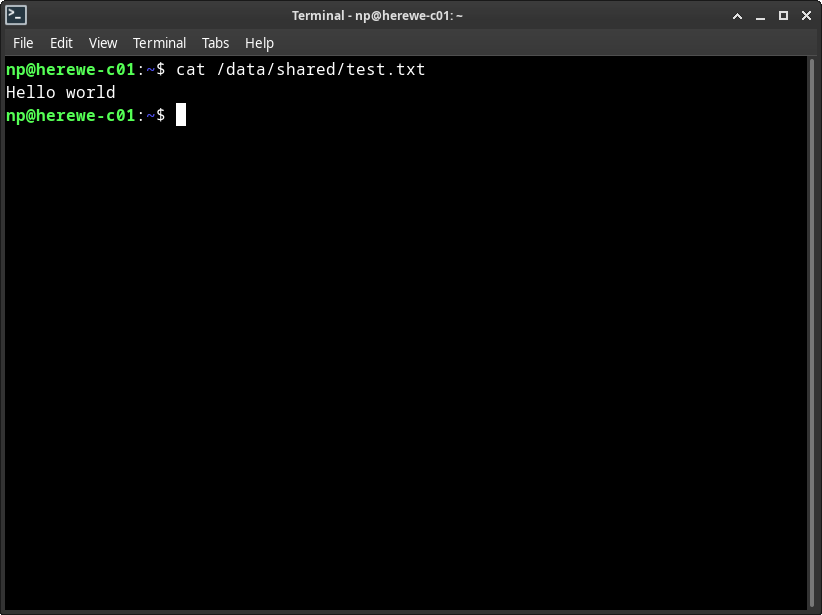
如此,就可以把配置和compose文件放心地放在共享存储上了。
提醒:别忘了在帐号里留个几块钱~
编写compose文件
Docker swarm的服务组织,使用完全和docker-compose兼容的描述文件,每一个compose文件,在服务组织上称为一个stack,可以包含若干个service,service就类似于k8s的pod了,是服务的描述单元,但是不像pod那样可以继续拆分,service下面就对应到单个镜像了。
Compose文件的格式参考。
通常会编写一组compose文件及相关的配置和脚本,为了管理方便,我用一个git repo来管理它们,并在服务器上同步他们。
首先,在compose目录下创建我们的第一个compose文件env.yaml,它对应一个叫做env的stack,将我们依赖的基础环境都放在里面。我尽量详细清楚地解释compose文件中的所有细节,并以注释的方式写下来。
首先是文件的顶层主干:
version: "3.8"
services:
networks:
herewe-net:
external: true
第一行表示compose文件版本3.8,这也是当前最新的版本了。
services段下面为服务列表,现在先把它留空,networks段下面为当前stack关联的所有docker网络,这里有一个,就是前面创建好的herewe-net(忘了的同学往前翻)。下面的external表示,它是由stack外创建的,也就是事先创建好的。如果external为false或者忽略本设置,herewe-net会随stack的创建而创建,也会随stack的撤销而消失。由于,我会有其它stack也关联这个网络,所以它就是一个external的了。
下面来干第一个服务:
traefik
我习惯把traefik写在第一个服务的位置(其实stack内的service书写顺序并不重要)。
Traefik是一个相当不错的玩意,它自己的定义是“边缘路由”,原本这是从反向代理和网关发展而来的。我在很多地方使用它,既由于它的动态配置特性,且它的性能基本可以满足小规模要求。感觉上,在处理HTTP API类型服务的代理时,大概相当于nginx的70%。对于绝大多数环境,API的瓶颈并不在HTTP上,而在于计算和IO。
首先在services段下,创建一个traefik:
traefik:
image: traefik:latest
volumes:
- /var/run/docker.sock:/var/run/docker.sock
- /data/herewe/traefik/etc/traefik.yml:/etc/traefik/traefik.yml
- /data/herewe/traefik/cert:/le
- /data/herewe/traefik/log:/log
networks:
- herewe-net
ports:
- 80:80
- 443:443
这里使用traefik的官方镜像,100MB左右。注意volumes下面的第一条,需要挂载主机的docker.sock,traefik需要通过它来感知swarm集群中服务的变化,实现动态配置。后面的三个就很好理解了,traefik.yml是配置文件,le用来保存证书,log就是log咯。
网络连接到herewe-net上,就可以和集群中其它的容器通讯。对外暴露80和443两个常规端口,如果你有啥特殊爱好,将它们添加好就可以了。
下面一段,是服务的部署配置,很关键的东西,我把注释写在里面:
deploy:
mode: global # 服务的mesh方式
placement:
constraints:
- node.role == manager # 只在manager节点上运行
update_config:
parallelism: 1 # 服务更新时容器的并发量
delay: 10s # 多个容器更新时的间隔时间
restart_policy:
condition: on-failure # 失败时自动重启
labels:
- "traefik.enable=true" # 这个服务需要被traefik感知(当然这个服务自己就是traefik)
- "traefik.http.services.traefik.loadbalancer.server.port=80" # 告诉traefik,服务对外的HTTP端口
- "traefik.http.routers.traefik.rule=Host(`traefik.env.g.herewe.tech`)" # 路由规则,这里是Host等于某域名,也可以写其它的一些规则,比如路径什么的
- "traefik.http.routers.traefik.service=api@internal" # 路由到哪里去,api@internal是traefik的后台服务
- "traefik.http.routers.traefik.entrypoints=websecure" # 路由的入口,websecure会在配置文件中描述
- "traefik.http.routers.traefik.tls.certresolver=le" # 自动申请TLS证书的配置,le也会在配置文件中描述
# Auth
- "traefik.http.routers.traefik.middlewares=traefik-auth" # traefik的后台,我不想让人随便看,所以放一个auth的中间件
- "traefik.http.middlewares.traefik-auth.basicauth.users=herewe:$$apr1$$jLdnAN0h$$W7algjI5nCLeSUlyz9cu.0" # BasicAuth的用户名密码,下面会去说明怎么生成这一大串东西
# Redirect
- "traefik.http.routers.traefik-http.rule=Host(`traefik.env.g.herewe.tech`)" # 又一条路由规则,还是上面相同的Host
- "traefik.http.routers.traefik-http.entrypoints=web" # 且入口是web,web也会在配置文件中说明
- "traefik.http.routers.traefik-http.middlewares=traefik-redirectscheme" # 当路由规则命中,使用一个重定向scheme的中间件
- "traefik.http.middlewares.traefik-redirectscheme.redirectscheme.scheme=https" # 把HTTP的scheme重定向为https
- "traefik.http.middlewares.traefik-redirectscheme.redirectscheme.permanent=true" # 重定向方式为HTTP 301
这一大堆,其实是traefik动态配置中精彩的东西,它完成了什么呢:
- 当用户访问了traefik.env.g.herewe.tech这个域名,且入口是websecure(其实就是https),就路由(代理)到traefik的后台服务上去。
- 如果https证书不存在或过期,自动申请一个来。
- 用户需要经过basic auth认证才能看。
- 当用户访问了traefik.env.g.herewe.tech这个域名且入口是web(其实就是普通的http),就301到https去,也就是变相实现了HSTS。
然后,来关注一下咱们的配置文件,traefik.yml:
global:
checkNewVersion: true # 检查新版本,这个其实没啥实际作用,它不会自动升级的
sendAnonymousUsage: true # 发送匿名使用情况报告给官方,支持社区发展,做个雷锋式好少年
serversTransport:
maxIdleConnsPerHost: 256 # 每host最大的空闲连接数,超过的会被杀掉,防止后端服务挂着太多
entryPoints:
web:
address: :80 # 入口<web>,监听地址是所有的80端口
websecure:
address: :443 # 入口<websecure>,监听地址是所有的443端口
metrics:
address: :8082 # 入口<metrics>,这其实是给prometheus exporter用的
providers:
docker: # 使用docker provider。provider就是traefik发现服务的方式,traefik支持很多的provider,像是k8s,consul啥的。
swarmMode: true # 打开swarm集群支持
exposedByDefault: false # 自动发现容器。默认值是true。当true时,traefik会自动关注swarm集群内所有的服务,当false时,只有服务配置了traefik.enable标签,它才会去搭理。
network: herewe-net # docker网络,还是herewe-net
watch: true # 关注docker event
certificatesResolvers:
le: # 这就是上面lables中用到的自动申请tls证书的配置<le>,le其实是let's Encrypt,我比较懒……
acme:
email: conan.np@gmail.com
storage: /le/acme.json # 证书放在那里
httpChallenge:
entryPoint: web # 自动申请证书时候challenge使用的入口。我当然会用web去申请websecure的证书,不会做出用websecure去给自己申请证书这种死循环。
log: # 日志,这里指的是traefik自身的运行日志,不是access
format: json # 日志格式,我要json的
filePath: /log/traefik.log # 日志写到哪里去
accessLog: # 这才是access
format: json # 我也要json,默认是CLF的,虽然比较适合人类阅读,但是对于结构化分析工具来说,没有json靠谱
bufferingSize: 5 # 写log的缓冲区,攒够多少行才批量写一次。对于访问量很大的场景,这个缓冲区可以大一些,缓解log appending的压力,但是过大的缓冲区也会导致traefik崩溃时丢log的数量变多,也会导致日志回放的实时性变差
metrics:
prometheus: # 打开prometheus exporter
entryPoint: metrics # prometheus exporter使用的入口
addEntryPointsLabels: true # 添加几个label
addRoutersLabels: true
addServicesLabels: true
tracing:
zipkin: # tracing上报给zipkin。traefik还支持jaeger,datadog啥的
httpEndpoint: http://env_zipkin:9411/api/v2/spans # zipkin在哪里
api:
dashboard: true # 支持后台服务的dashboard,如果没有这个,上面设置的traefik自身路由是什么都看不到的
以上配置完成了:
- 在docker swarm中监听服务变化。这里需要注意的是,服务事件只能在swarm的manager节点上监听到,所以traefik只能去挂载manager的docker.sock,worker的不可以,所以这里我只让traefik运行在manager上,然后挂载本地的docker.sock。
- 打开了三个入口,分别是web、websecure和metrics。
- 配置了let's Encrypt
- 配置了prometheus exporter和zipkin tracing
- 配置了日志
关于
- 关于HTTPChallenge,可以参考
- Swarm不支持端口发现,所以运行在swarm集群内的服务,注册进traefik的时候需要显式提供服务端口。
- BasicAuth那个一长串的用户名:密码对,可以用htpasswd(Apache提供的)工具来生成:echo $(htpasswd -nB user) | sed -e s/\\$/\\$\\$/g
上线
我打算在三个manager节点上都运行traefik,所以,分别配置三个域名在路由规则上。
通过git把配置和compose文件同步到其中一台manager上,哪个都可以,这里我选在q01上:
version: "3.8"
services:
# Traefik gateway
traefik:
image: traefik:latest
volumes:
- /var/run/docker.sock:/var/run/docker.sock
- /data/shared/env/tencent-cloud/swarm/prod/etc/traefik/traefik.yml:/etc/traefik/traefik.yml # 配置文件直接使用共享存储内git repo中的
- /data/shared/traefik/cert:/le # 证书是可以共享的
- /data/herewe/traefik/log:/log # 服务log不需要共享
networks:
- herewe-net
ports:
- 80:80
- 443:443
depends_on:
- loki
- zipkin
deploy:
mode: global
placement:
constraints:
- node.role == manager
update_config:
parallelism: 1
delay: 10s
restart_policy:
condition: on-failure
labels:
- "traefik.enable=true"
- "traefik.http.services.traefik.loadbalancer.server.port=80"
- "traefik.http.routers.traefik.rule=Host(`traefik.env.b.herewe.tech`, `traefik.env.b1.herewe.tech`, `traefik.env.b2.herewe.tech`, `traefik.env.b3.herewe.tech`)" # 多写几个域名
- "traefik.http.routers.traefik.service=api@internal"
- "traefik.http.routers.traefik.entrypoints=websecure"
- "traefik.http.routers.traefik.tls.certresolver=le"
# Auth
- "traefik.http.routers.traefik.middlewares=traefik-auth"
- "traefik.http.middlewares.traefik-auth.basicauth.users=herewe:$$apr1$$jLdnAN0h$$W7algjI5nCLeSUlyz9cu.0"
# Redirect
- "traefik.http.routers.traefik-http.rule=Host(`traefik.env.b.herewe.tech`, `traefik.env.b1.herewe.tech`, `traefik.env.b2.herewe.tech`, `traefik.env.b3.herewe.tech`)"
- "traefik.http.routers.traefik-http.entrypoints=web"
- "traefik.http.routers.traefik-http.middlewares=traefik-redirectscheme"
- "traefik.http.middlewares.traefik-redirectscheme.redirectscheme.scheme=https"
- "traefik.http.middlewares.traefik-redirectscheme.redirectscheme.permanent=true"
networks:
herewe-net:
external: true
在各个manager节点上创建好相应的目录后,从任意一个manager上执行:
docker stack deploy --compose-file /data/shared/env/tencent-cloud/swarm/prod/compose/env.yaml env
使用env.yaml文件启动stack,名字叫env。成功后,可以通过swarm命令查看stack和相应的service列表:
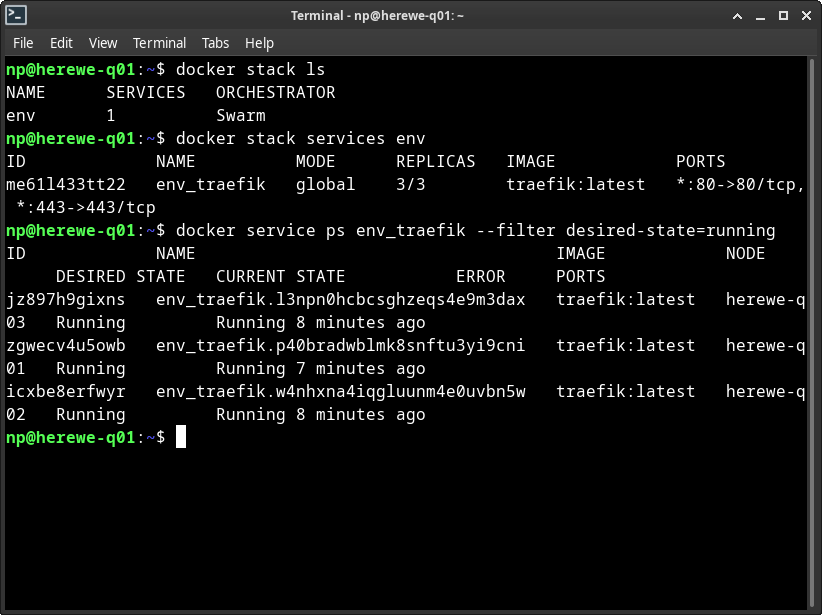
可以看到,集群上启动了一个名字叫env的stack,这个stack下面有一个service,名字叫env_traefik(swarm会自动命名service为[STACK]_[SERVICE]),这个service的部署类型为global,分别在q01、q02、q03三个节点上启动了三个副本。
Traefik会自动在let'sEncrypt上申请证书,成功后,可以尝试访问这三个节点(b1、b2、b3):
尝试访问,需要输入前面设置好的用户名和密码,成功之后,显示traefik的dashboard:
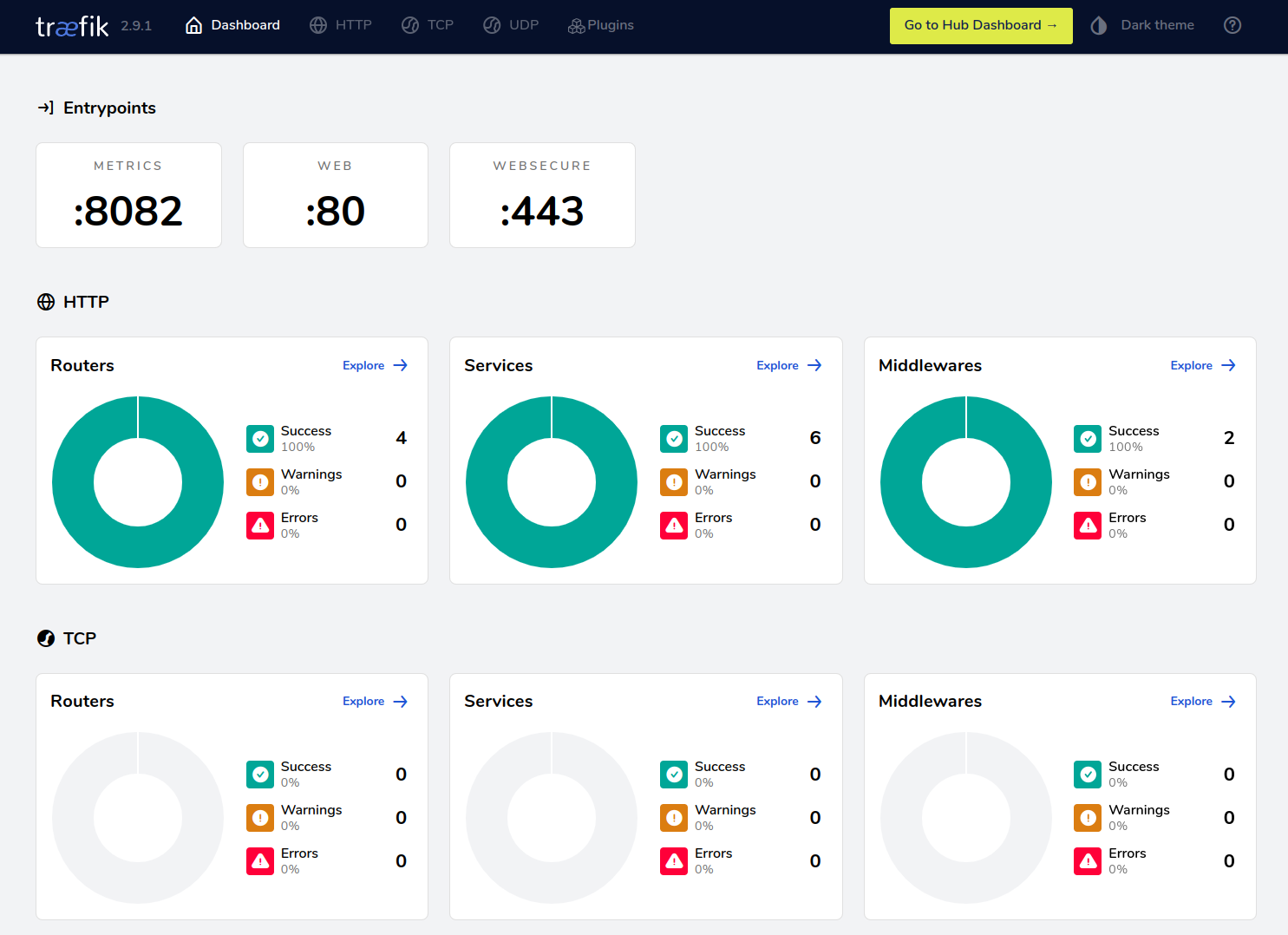
现在,traefik已经可用了。下面,还准备再起一些服务,只需要一个副本的那种,所以,我们需要给q01写一个label,用于区别其它两个manager:
docker node update --label-add env=main herewe-q01
这样,就给q01添加了一个K/V形式的label:env=main,我们可以用它来与其它的节点区别对待。下面,我们在q01上起一些别的服务:
Zipkin
OpenZipkin我只是用来做简单的tracing,甚至都没打算落地数据,所以只是起了一个单副本的service,没有任何外部存储,数据只在内存维护:
# Service : Zipkin tracing
zipkin:
image: openzipkin/zipkin-slim:latest # zipkin-slim镜像比完整的zipkin镜像小一些
networks:
- herewe-net
deploy:
mode: global
placement:
constraints:
- node.labels.env == main # 只在env==main,也就是q01上启动
update_config:
parallelism: 1
delay: 2s
restart_policy:
condition: on-failure
labels:
- "traefik.enable=true"
- "traefik.http.services.zipkin.loadbalancer.server.port=9411" # Zipkin的http端口是9411
- "traefik.http.routers.zipkin.rule=Host(`zipkin.env.b.herewe.tech`)"
- "traefik.http.routers.zipkin.entrypoints=websecure"
- "traefik.http.routers.zipkin.tls.certresolver=le"
# Auth
- "traefik.http.routers.zipkin.middlewares=zipkin-auth"
- "traefik.http.middlewares.zipkin-auth.basicauth.users=herewe:$$apr1$$jLdnAN0h$$W7algjI5nCLeSUlyz9cu.0"
# Redirect
- "traefik.http.routers.zipkin-http.rule=Host(`zipkin.env.b.herewe.tech`)"
- "traefik.http.routers.zipkin-http.entrypoints=web"
- "traefik.http.routers.zipkin-http.middlewares=zipkin-redirectscheme"
- "traefik.http.middlewares.zipkin-redirectscheme.redirectscheme.scheme=https"
- "traefik.http.middlewares.zipkin-redirectscheme.redirectscheme.permanent=true"
更新compose文件,再deploy一次env,可以看到,zipkin只在q01上起了一个副本:
访问对应host,可以看到zipkin活着了:
下面,再来做portainer,一样起在q01上。
Portainer
Portainer可以方便地做容器环境管理,用过就知道,是真的好用。咱们来继续编辑env stack:
# Portainer
portainer:
image: portainer/portainer-ce:latest # 这里要用-ce的镜像
volumes:
- /var/run/docker.sock:/var/run/docker.sock
- /data/herewe/portainer/data:/data
networks:
- herewe-net
deploy:
mode: global
placement:
constraints:
- node.labels.env == main # 照旧,起在q01上
update_config:
parallelism: 1
delay: 10s
restart_policy:
condition: on-failure
labels:
- "traefik.enable=true"
- "traefik.http.services.portainer.loadbalancer.server.port=9000" # Portainer的http端口是9000
- "traefik.http.routers.portainer.rule=Host(`portainer.env.b.herewe.tech`)"
- "traefik.http.routers.portainer.entrypoints=websecure"
- "traefik.http.routers.portainer.tls.certresolver=le"
# Redirect
- "traefik.http.routers.portainer-http.rule=Host(`portainer.env.b.herewe.tech`)"
- "traefik.http.routers.portainer-http.entrypoints=web"
- "traefik.http.routers.portainer-http.middlewares=portainer-redirectscheme"
- "traefik.http.middlewares.portainer-redirectscheme.redirectscheme.scheme=https"
- "traefik.http.middlewares.portainer-redirectscheme.redirectscheme.permanent=true"
创建好对应的目录,更新compose后重新deploy stack。Portainer第一次启动,要在300秒内初始化,窗口过了就不能再设置了,需要重启服务(service update)。
初始化后,直接打开Local环境,即可看到swarm集群内的各种资源:
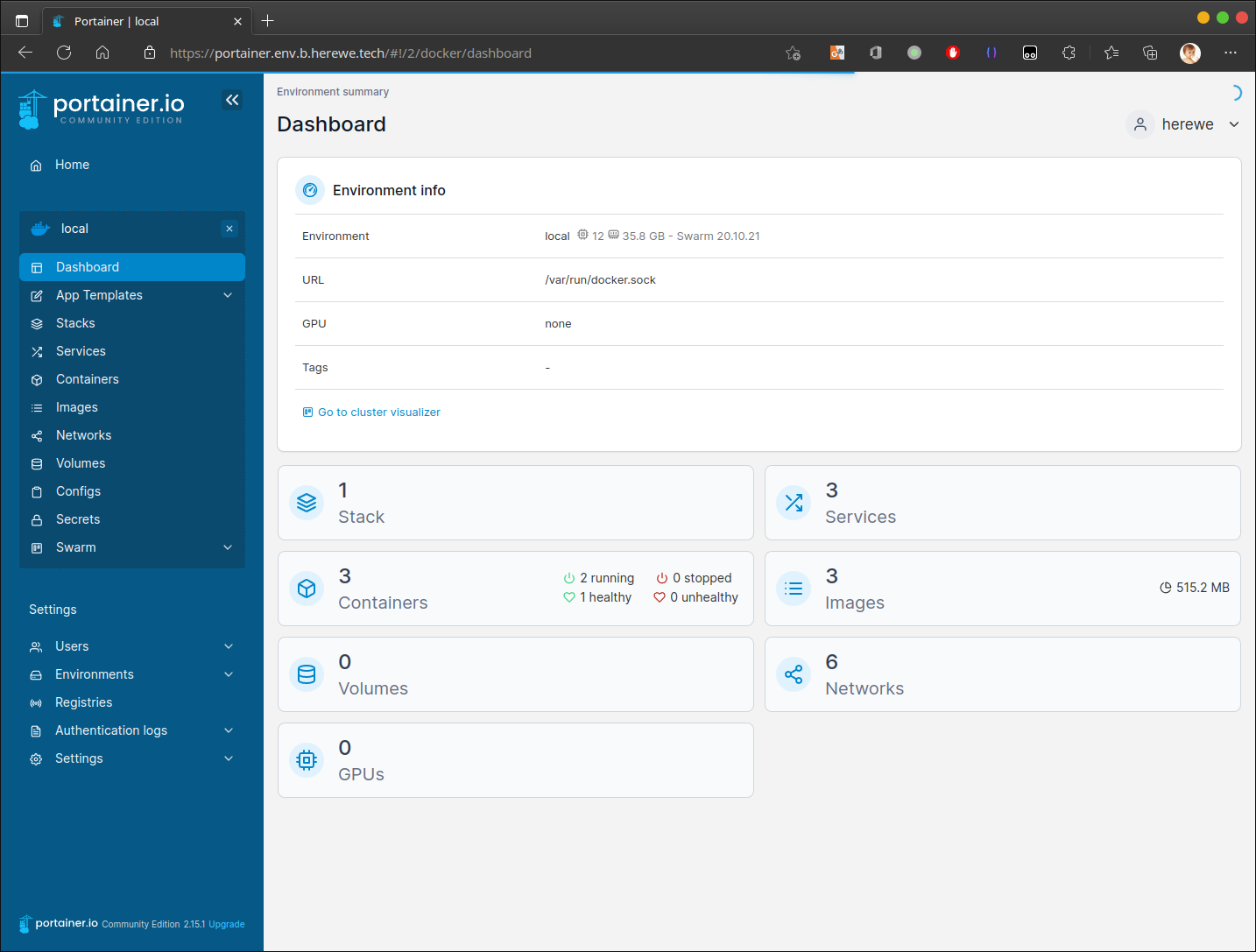
Portainer怎么使用,目前不在本篇范围内,有空我再去写吧。
下面,就是咱们服务的运行保障,伟大的prometheus了:
Prometheus

继续编辑env.yaml,添加prometheus:
# Service : Prometheus - Metrics
prometheus:
image: prom/prometheus:latest
volumes:
- /data/shared/env/tencent-cloud/swarm/prod/etc/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml # Prometheus的静态配置文件
- /data/herewe/prometheus/data:/prometheus # 时序数据库存储
networks:
- herewe-net
deploy:
mode: global
placement:
constraints:
- node.labels.env == main
update_config:
parallelism: 1
delay: 2s
restart_policy:
condition: on-failure
labels:
- "traefik.enable=true"
- "traefik.http.services.prometheus.loadbalancer.server.port=9090"
- "traefik.http.routers.prometheus.rule=Host(`prometheus.env.b.herewe.tech`)"
- "traefik.http.routers.prometheus.entrypoints=websecure"
- "traefik.http.routers.prometheus.tls.certresolver=le"
# Auth
- "traefik.http.routers.prometheus.middlewares=prometheus-auth"
- "traefik.http.middlewares.prometheus-auth.basicauth.users=herewe:$$apr1$$jLdnAN0h$$W7algjI5nCLeSUlyz9cu.0"
# Redirect
- "traefik.http.routers.prometheus-http.rule=Host(`prometheus.env.b.herewe.tech`)"
- "traefik.http.routers.prometheus-http.entrypoints=web"
- "traefik.http.routers.prometheus-http.middlewares=prometheus-redirectscheme"
- "traefik.http.middlewares.prometheus-redirectscheme.redirectscheme.scheme=https"
- "traefik.http.middlewares.prometheus-redirectscheme.redirectscheme.permanent=true"
配置文件prometheus.yml:
global:
scrape_interval: 15s
external_labels:
monitor: "codelab-monitor"
scrape_configs:
- job_name: "prometheus" # 第一个job,就是prometheus本身
scrape_interval: 5s # 5秒刷新一次
static_configs:
- targets: ["localhost:9090"] # 读localhost:9090/metrics
创建目录,这里需要注意的是,prometheus的数据目录,需要将owner设置为65534:65534,更新compose,重启stack:
Prometheus很强大,但是它的界面过于简单,通常,大家都会搭配grafana共同食用,所以,下面我们来弄一个grafana:
Grafana
继续在stack中创建:
# Grafana
grafana:
image: grafana/grafana:latest
volumes:
- /data/herewe/grafana/data:/var/lib/grafana
networks:
- herewe-net
deploy:
mode: global
placement:
constraints:
- node.labels.env == main
update_config:
parallelism: 1
delay: 2s
restart_policy:
condition: on-failure
labels:
- "traefik.enable=true"
- "traefik.http.services.grafana.loadbalancer.server.port=3000"
- "traefik.http.routers.grafana.rule=Host(`grafana.env.b.herewe.tech`)"
- "traefik.http.routers.grafana.entrypoints=websecure"
- "traefik.http.routers.grafana.tls.certresolver=le"
# Redirect
- "traefik.http.routers.grafana-http.rule=Host(`grafana.env.b.herewe.tech`)"
- "traefik.http.routers.grafana-http.entrypoints=web"
- "traefik.http.routers.grafana-http.middlewares=grafana-redirectscheme"
- "traefik.http.middlewares.grafana-redirectscheme.redirectscheme.scheme=https"
- "traefik.http.middlewares.grafana-redirectscheme.redirectscheme.permanent=true"
Grafana的存储目录,需要把UID设置成472。创建目录,更新compose,重新deploy:

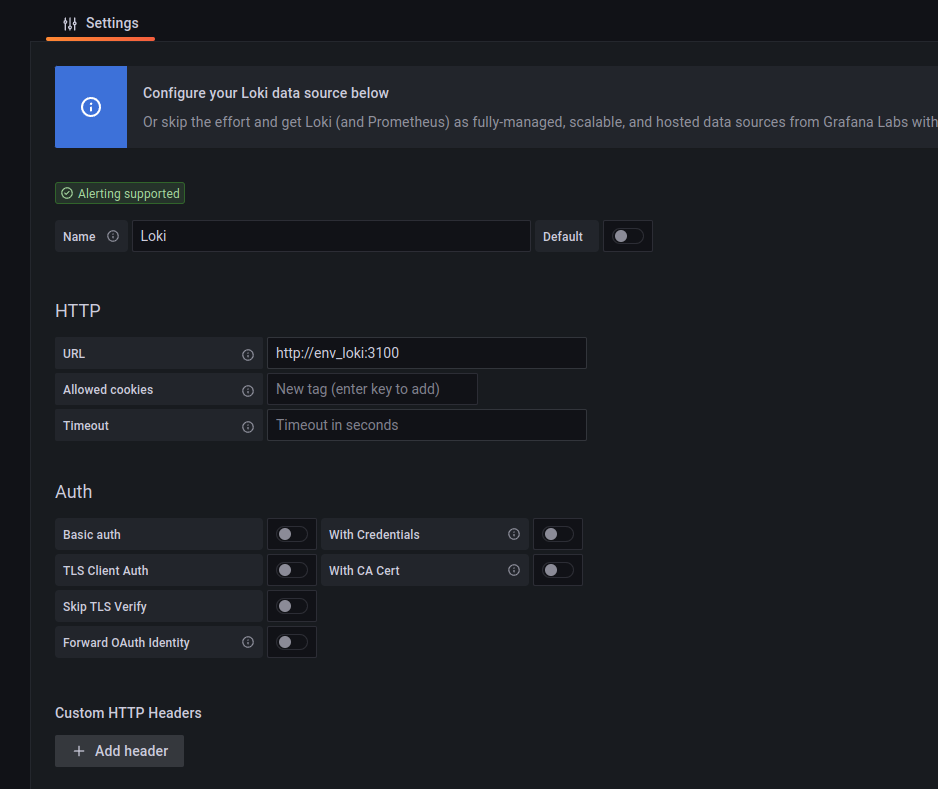
Grafana的初始化用户名和密码都是admin,登录后第一步会提示修改admin的密码。简单设置后,添加第一个数据源,也就是prometheus,这里的地址,通过swarm内部的overlay网络实现服务发现,直接用服务名作为dns主机名即可:
导入两个相关的dashboard,即可在grafana中查看prometheus指标了:
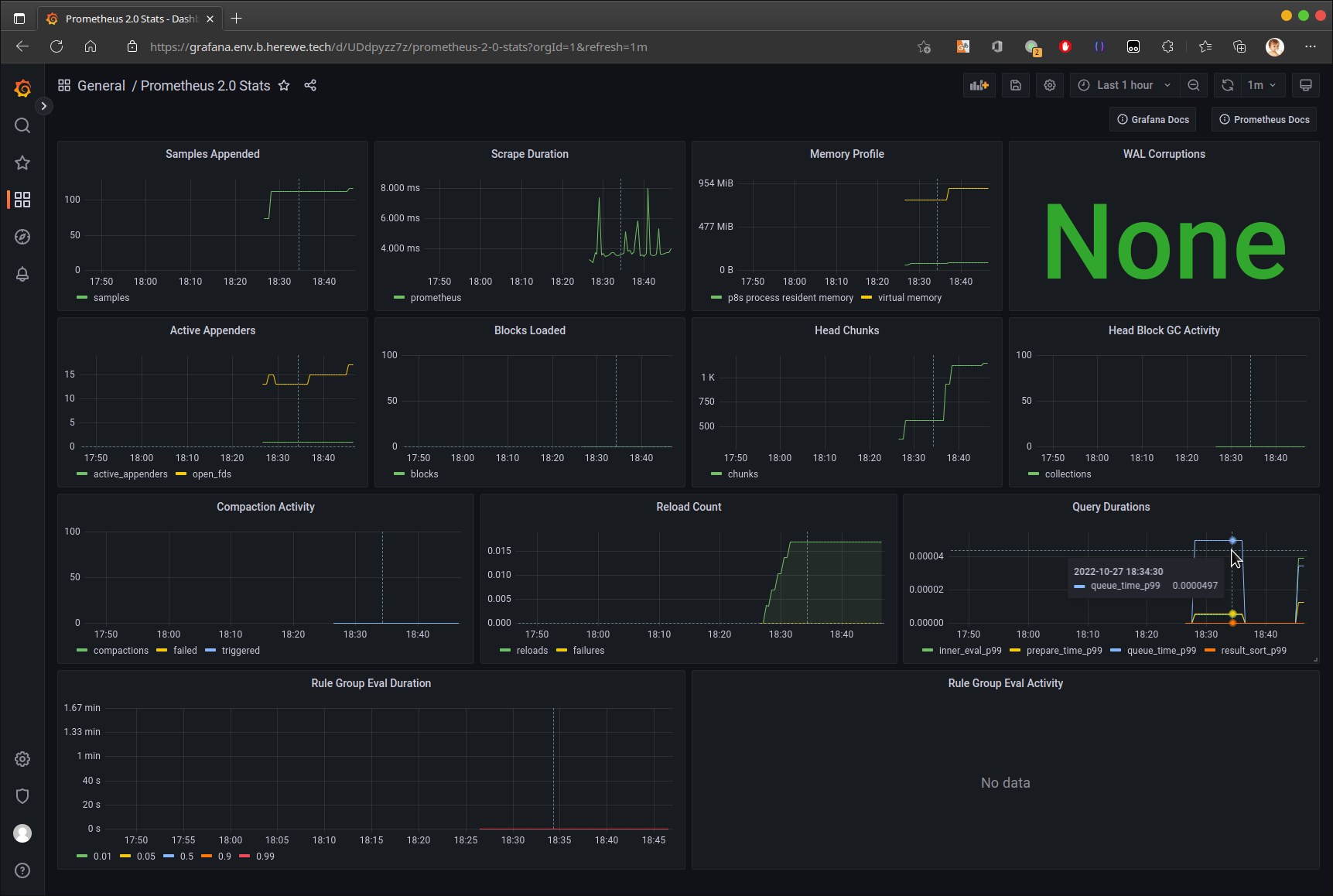
至此,prometheus+grafana的神仙组合成功会师。
接下来,是我们最后一个重量级依赖——日志。流行的ELK组合一类的,我还是觉得内耗有些高,不太适合我这种小作坊,所以我选择了grafana的日志新贵:
Loki
Loki虽然是新贵,但是官方文档不那么负责,坑是比较多的,这里我们稍稍详细一些,把它弄下来。首先,我们还是继续更新stack:
# Loki
loki:
image: grafana/loki:latest
volumes:
- /data/shared/env/tencent-cloud/swarm/prod/etc/loki/loki.yml:/etc/loki.yml
- /data/herewe/loki/data:/loki
command: "-config.file=/etc/loki.yml" # 用上面的配置文件启动
networks:
- herewe-net
ports:
- 3100:3100 # 这里需要把端口expose出去
deploy:
labels:
- traefik.enable=false # loki不需要被traefik代理
mode: global
placement:
constraints:
- node.labels.env == main
update_config:
parallelism: 1
delay: 2s
restart_policy:
配置文件loki.yml:
auth_enabled: false
server:
http_listen_port: 3100 # HTTP监听地址
ingester:
lifecycler:
address: 127.0.0.1
ring:
kvstore:
store: inmemory
replication_factor: 1
final_sleep: 0s
wal:
dir: /loki/wal # wal数据存在哪里
schema_config:
configs:
- from: 2020-01-01
store: boltdb
object_store: filesystem
schema: v11
index:
prefix: index_
period: 168h # 每168小时,也就是7天,分割一个新表。如果你的日志量很大,可以考虑调整这个值,以防止表过大
storage_config:
boltdb:
directory: /loki/index # KV库(索引)保存位置
filesystem:
directory: /loki/chunks # 数据块保存位置
frontend:
address: 0.0.0.0 # 允许的来源
frontend.address这个配置非常重要,它表示被允许push日志的来源,0.0.0.0表示允许所有IPv4地址。loki的默认值为127.0.0.1,只允许自己和自己玩,这在swarm环境中会出现接收不到日志的情况。
创建目录,loki的数据目录需要修改UID和GID为10001,更新compose和stack:
然后,我们在grafana中添加这个loki数据源:
这个时候,grafana会告警,虽然添加数据源成功,但是里面没有任何日志标签,这也是正常的,因为咱们的loki中还没有日志,下面我们来看看如何把日志弄进去。
日志是一个很大的话题,细节也不在本篇讨论范围,等不懒的时候再细说吧。关于loki,可以参考[文档]。
通常,我们需要使用promtail采集服务的日志,在docker环境下,我们可以简单地使用loki driver把docker log重定向到loki中。
我们需要在节点上安装loki的docker plugin,执行:
docker plugin install grafana/loki-docker-driver:latest --alias loki --grant-all-permissions
安装成功后,会自动启用:
这里,我把traefik和grafana的日志定向到loki里,在compose文件中的traefik和grafana service中添加:
logging:
driver: loki
options:
loki-url: "http://herewe-q01:3100/loki/api/v1/push"
使用刚刚安装的loki plugin作为docker的log driver,这并不会影响原始的logging drvier,也就是local json-file,本地日志还是一样会输出的。
关注这里的loki-url,地址是herewe-q01,也就是q01节点的内网ipv4地址。此处的视角是docker引擎,而不是overlay,所以不能使用loki服务的内部服务名,只能用docker引擎可以直接解析到的地址。这也就是为什么,在上面我们需要把loki的3100端口expose到主机。
另一个需要注意的地方,就是loki配置中的frontend地址,前面我们留下的是0.0.0.0,这是个ipv4地址,所以loki-url中也必须接续到ipv4地址上。如果我们需要ipv6支持,frontend的address需要修改成“:::”。
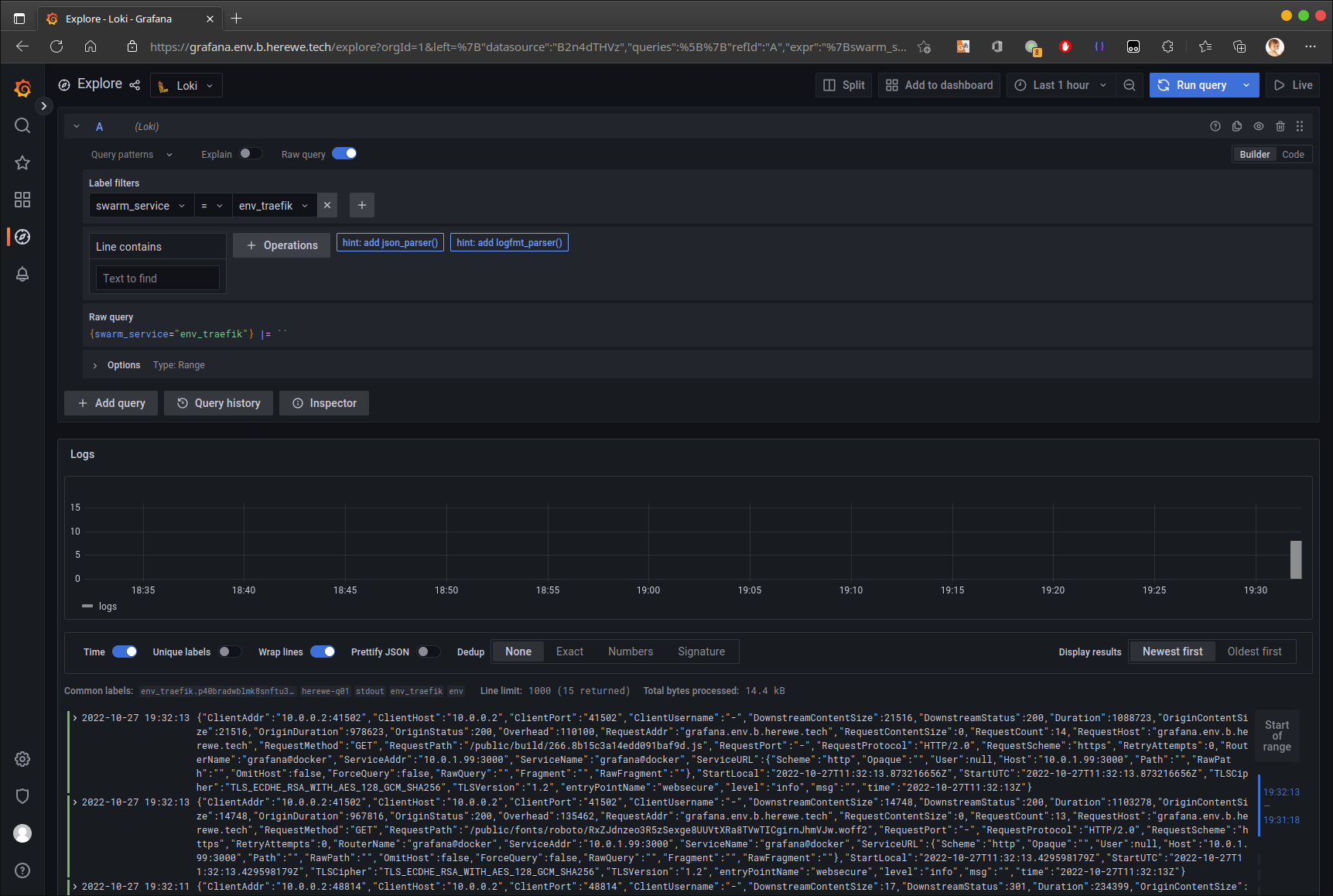
更新compose,刷新stack后,咱就可以在grafana的explore loki中看到来自traefik和grafana的日志了:
日志也齐了,咱们来丰富一下伟大的grafana。首先,我想要在grafana中看到所有节点的状态,使用node-exporter,让prometheus感知到这些状态。
Node-exporter
需要以global方式,在所有节点上都启动一个node-exporter:
# Node Exporter
node-exporter:
image: prom/node-exporter:latest
command:
- "--path.rootfs=/host"
volumes:
- /:/host:ro,rslave # 把主机的根目录挂载到容器的/host上,使得node-exporter可以读到/proc等信息以获得主机状态
networks:
- herewe-net
ports:
- 9100:9100 # 访问能力需要expose
deploy:
labels:
- traefik.enable=false
mode: global
update_config:
parallelism: 1
delay: 2s
restart_policy:
condition: on-failure
更新,查看状态:
接下来,修改prometheus的静态配置文件,添加node-exporter的采集:
- job_name: "node"
scrape_interval: 5s
static_configs:
- targets: ["10.0.16.10:9100", "10.0.16.16:9100", "10.0.16.17:9100", "172.17.16.14:9100", "172.17.16.16:9100", "172.17.16.17:9100"]
修改配置文件,不需要重新deploy stack,只需要重启prometheus服务即可:
docker service update env_prometheus --force
在grafana中,添加编号为1860的dashboard:
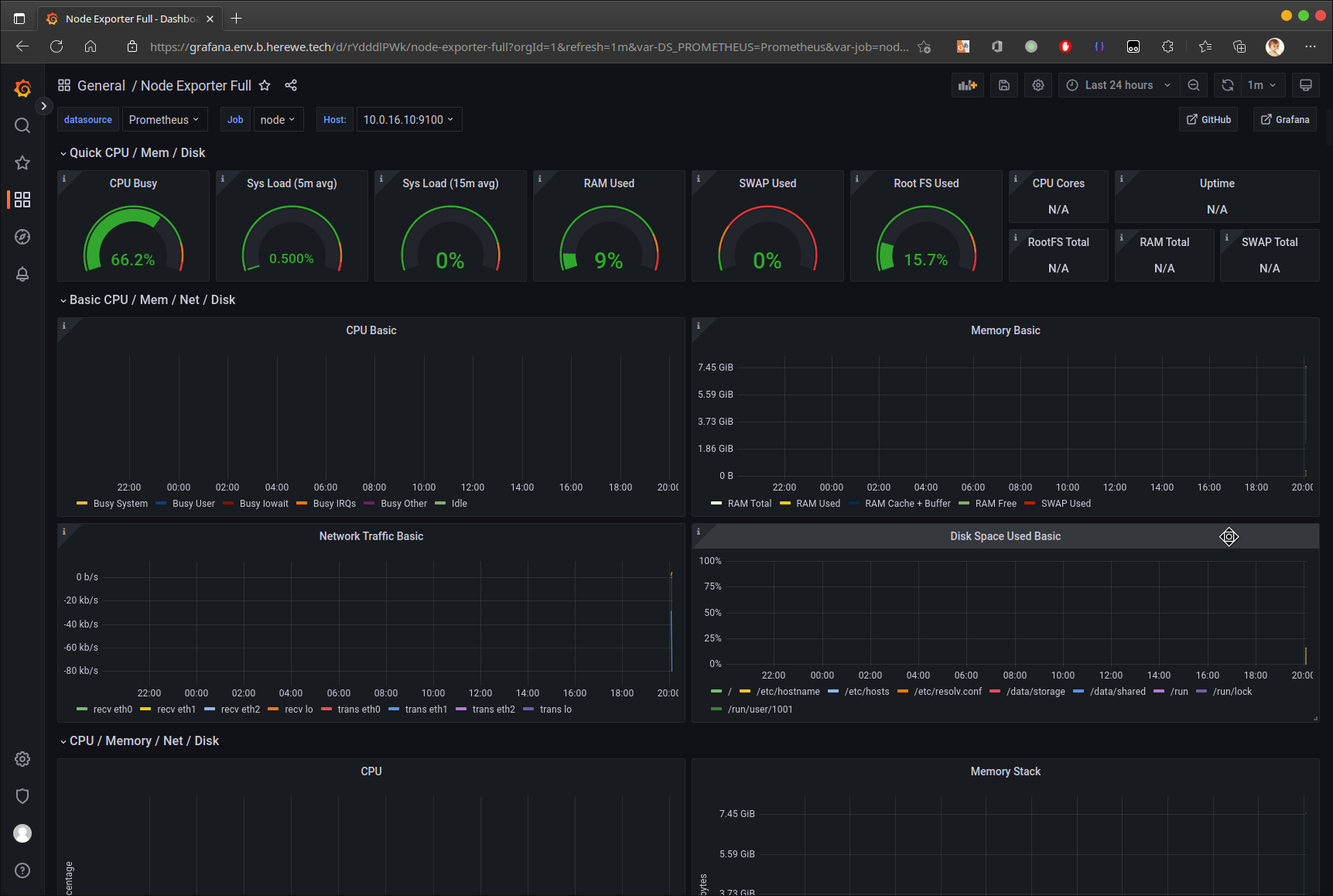
添加成功后,在dashboard中就可以看到节点的状态了:
Traefik metrics
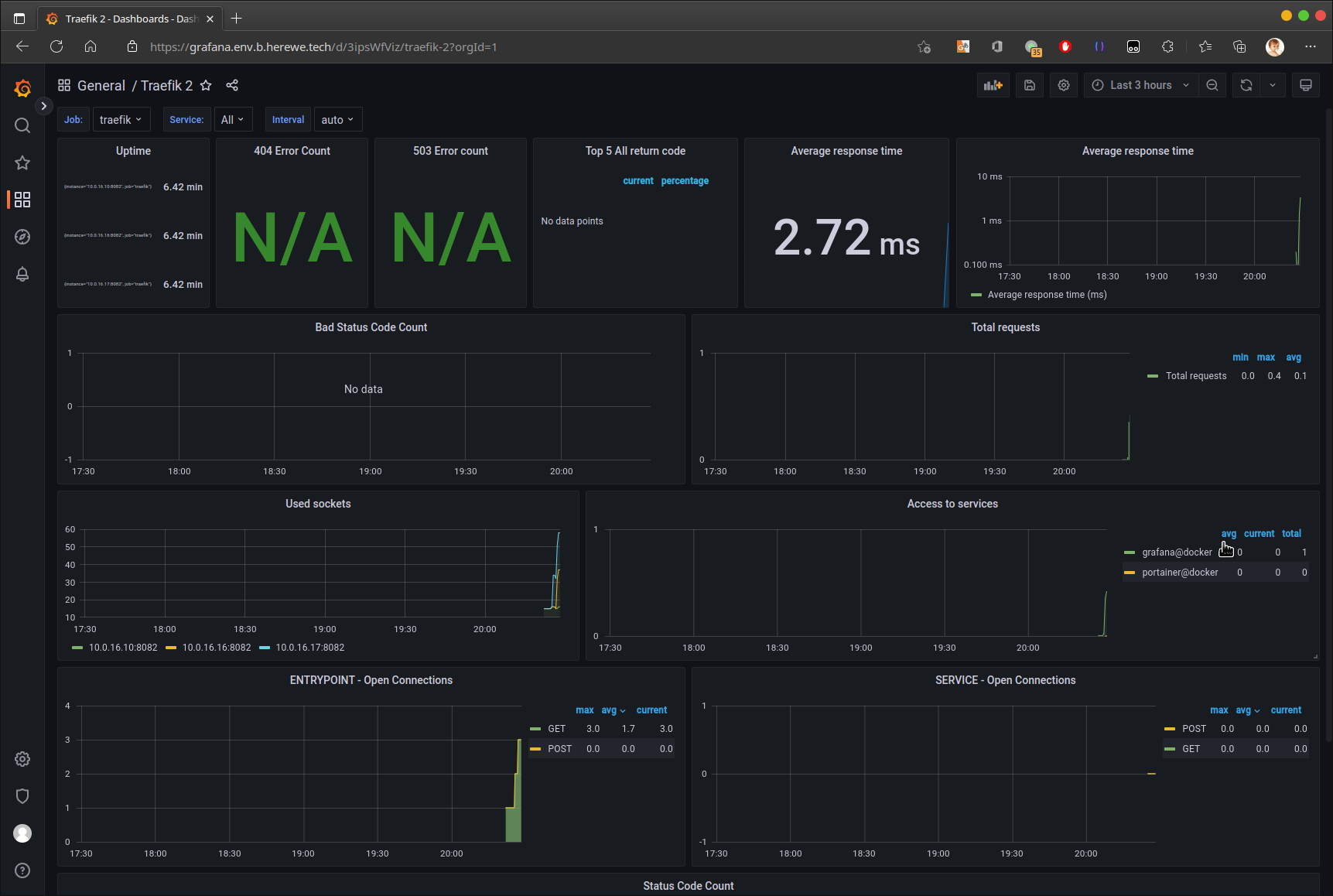
Traefik也是可以被prometheus采集的:
- job_name: "traefik"
scrape_interval: 5s
static_configs:
- targets: ["10.0.16.10:8082", "10.0.16.16:8082", "10.0.16.17:8082"]
记得把traefik的8082端口也expose了。重启prometheus后,在grafana中添加ID为11462的dashboard:
容器资源采集
继续编辑compose,添加cadvisor:
# Service : cAdvisor
cadvisor:
image: gcr.lank8s.cn/cadvisor/cadvisor:latest # 由于gcr.io在国内访问困难,这里换了一个tag
volumes:
- /:/rootfs:ro
- /var/run:/var/run:ro
- /sys:/sys:ro
- /dev/disk/:/dev/disk:ro
- /var/lib/docker:/var/lib/docker:ro
networks:
- herewe-net
ports:
- 8080:8080
deploy:
mode: global
placement:
constraints:
- node.role == manager
update_config:
parallelism: 1
delay: 2s
restart_policy:
condition: on-failure
labels:
- "traefik.enable=true"
- "traefik.http.services.cadvisor.loadbalancer.server.port=8080"
- "traefik.http.routers.cadvisor.rule=Host(`cadvisor.env.b.herewe.tech`)"
- "traefik.http.routers.cadvisor.entrypoints=websecure"
- "traefik.http.routers.cadvisor.tls.certresolver=le"
# Auth
- "traefik.http.routers.cadvisor.middlewares=cadvisor-auth"
- "traefik.http.middlewares.cadvisor-auth.basicauth.users=herewe:$$apr1$$jLdnAN0h$$W7algjI5nCLeSUlyz9cu.0"
# Redirect
- "traefik.http.routers.cadvisor-http.rule=Host(`cadvisor.env.b.herewe.tech`)"
- "traefik.http.routers.cadvisor-http.entrypoints=web"
- "traefik.http.routers.cadvisor-http.middlewares=cadvisor-redirectscheme"
- "traefik.http.middlewares.cadvisor-redirectscheme.redirectscheme.scheme=https"
- "traefik.http.middlewares.cadvisor-redirectscheme.redirectscheme.permanent=true"
在prometheus中添加cadvisor:
- job_name: "cadvisor"
scrape_interval: 5s
static_configs:
- targets: ["10.0.16.10:8080", "10.0.16.16:8080", "10.0.16.17:8080"]
更新prometheus服务,并在grafana中添加ID为10619的dashboard:
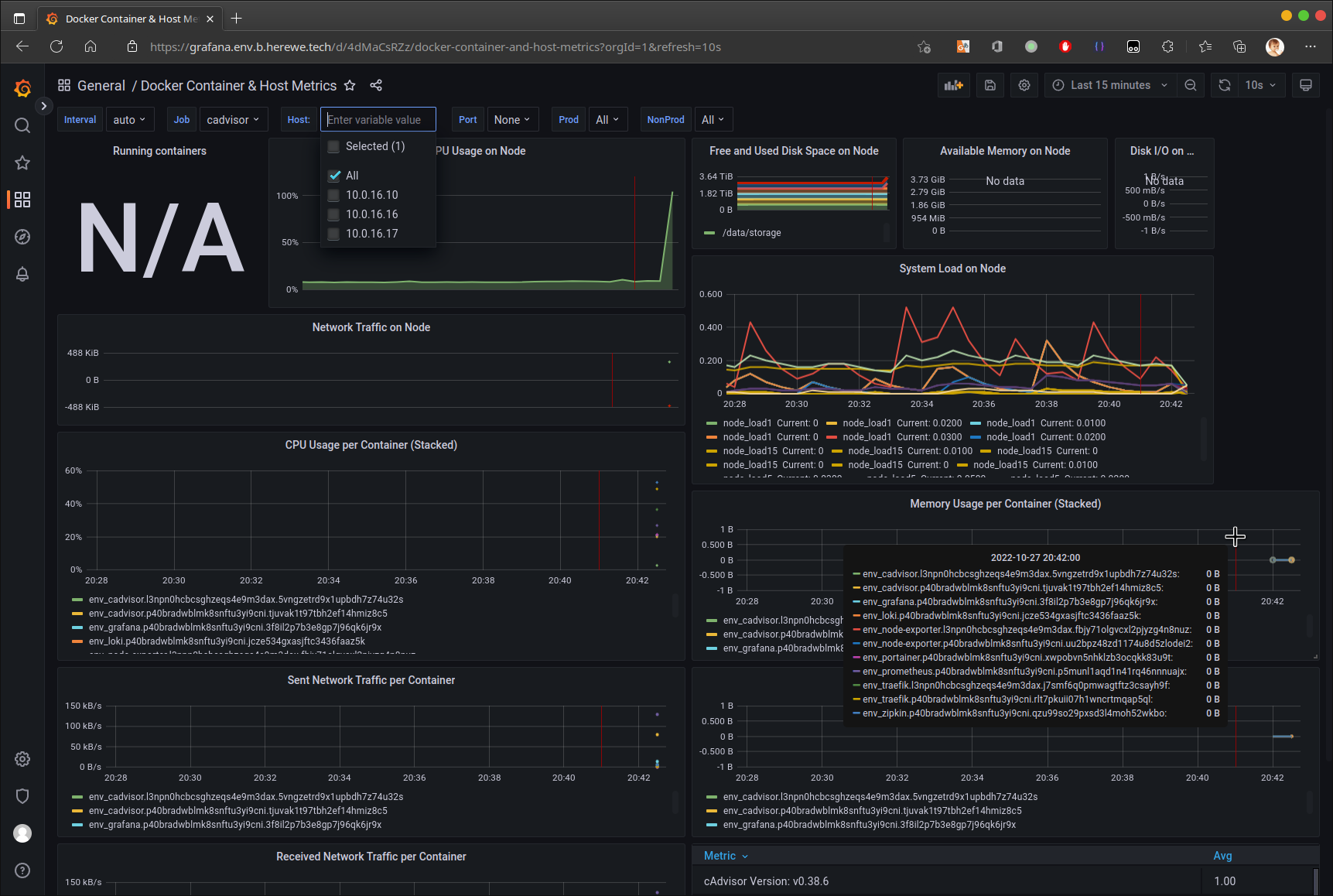
现在,咱们的dashboard差不多了,其实grafana里可玩的东西很多,大家可以慢慢发现。
既然,指标已经都搞出来了,那么当指标不正常的时候,咱们希望可以得到告警,所以,下面我们来处理运维方面的告警
Alertmanager
Alertmanager是prometheus自家的告警服务,由prometheus的指标规则触发。Alertmanager可以当作是一个路由,将相应的告警信息通过配置好的provider通道发送。以国内的环境来说,alertmanager支持的通道类型并不丰富,仅内置了企业微信的接口,但是可以通过万能的webhook来弥补,通过定制服务进行二级分发,比如接入短信通道等。
在这个实例中,我用slack来接收告警信息。
首先,扩展compose,添加alertmanager:
# Service : Alertmanager - Alert
alertmanager:
image: prom/alertmanager:latest
depends_on:
- prometheus
volumes:
- /data/shared/env/tencent-cloud/swarm/prod/etc/alertmanager/alertmanager.yml:/etc/alertmanager/alertmanager.yml
- /data/shared/env/tencent-cloud/swarm/prod/etc/alertmanager/templates:/templates # 消息模板
- /data/herewe/alertmanager/data:/alertmanager # 队列存储
command:
- "--config.file=/etc/alertmanager/alertmanager.yml"
- "--log.level=debug" # 多打点log,看看告警消息有没有发出去呢
networks:
- herewe-net
deploy:
mode: global
placement:
constraints:
- node.labels.env == main
update_config:
parallelism: 1
delay: 2s
restart_policy:
condition: on-failure
labels:
- "traefik.enable=true"
- "traefik.http.services.alertmanager.loadbalancer.server.port=9093"
- "traefik.http.routers.alertmanager.rule=Host(`alertmanager.env.b.herewe.tech`)"
- "traefik.http.routers.alertmanager.entrypoints=websecure"
- "traefik.http.routers.alertmanager.tls.certresolver=le"
# Auth
- "traefik.http.routers.alertmanager.middlewares=alertmanager-auth"
- "traefik.http.middlewares.alertmanager-auth.basicauth.users=herewe:$$apr1$$jLdnAN0h$$W7algjI5nCLeSUlyz9cu.0"
# Redirect
- "traefik.http.routers.alertmanager-http.rule=Host(`alertmanager.env.b.herewe.tech`)"
- "traefik.http.routers.alertmanager-http.entrypoints=web"
- "traefik.http.routers.alertmanager-http.middlewares=alertmanager-redirectscheme"
- "traefik.http.middlewares.alertmanager-redirectscheme.redirectscheme.scheme=https"
- "traefik.http.middlewares.alertmanager-redirectscheme.redirectscheme.permanent=true"
在[这里]创建一个新的slack app,成功后会返回一个api_url,下面要用。新创建的app自己保存好:
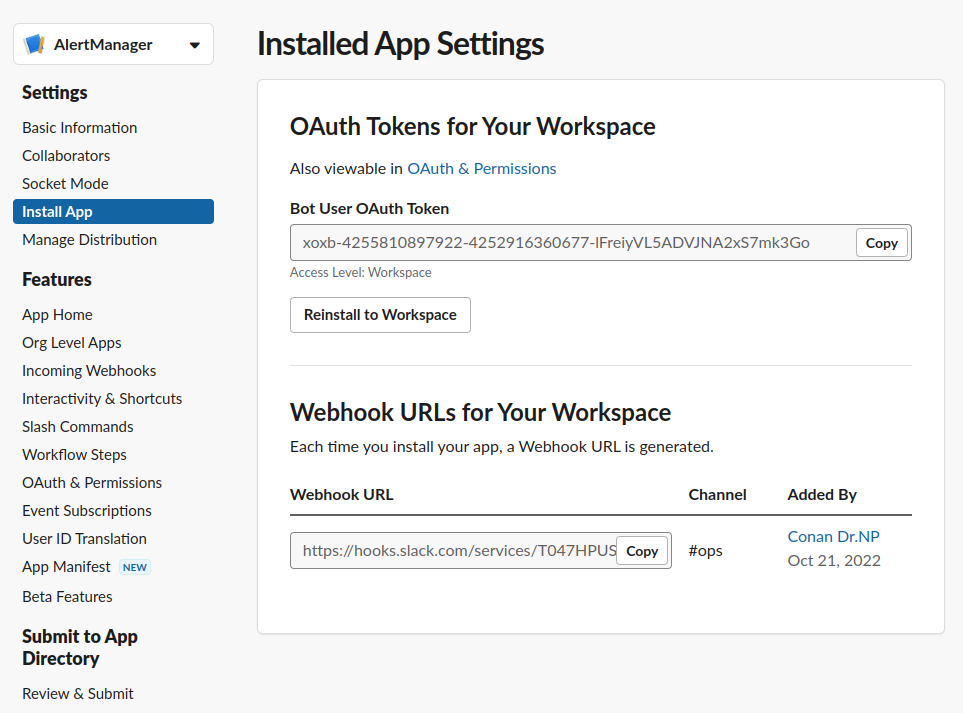
配置文件alertmanager.yml:
route:
group_by: ["alertname"] # 根据上游(prometheus)来的告警规则名分组
receiver: "slack" # 发送至slack这个通道
receivers:
- name: "slack" # 通道slack配置
slack_configs:
- channel: "#ops" # slack的频道
api_url: "https://hooks.slack.com/services/{TOKEN}" # slack组织申请到的TOKEN
color: '{{ template "slack.color" . }}'
title: '{{ template "slack.title" . }}'
text: '{{ template "slack.text" . }}'
templates:
- /templates/*.tmpl # 模板文件
创建一个消息模板文件slack.tmpl:
{{ define "__alert_silence_link" -}}
{{ .ExternalURL }}/#/silences/new?filter=%7B
{{- range .CommonLabels.SortedPairs -}}
{{- if ne .Name "alertname" -}}
{{- .Name }}%3D"{{- .Value -}}"%2C%20
{{- end -}}
{{- end -}}
alertname%3D"{{- .CommonLabels.alertname -}}"%7D
{{- end }}
{{ define "__alert_severity" -}}
{{- if eq .CommonLabels.severity "critical" -}}
*Severity:* `Critical`
{{- else if eq .CommonLabels.severity "warning" -}}
*Severity:* `Warning`
{{- else if eq .CommonLabels.severity "info" -}}
*Severity:* `Info`
{{- else -}}
*Severity:* :question: {{ .CommonLabels.severity }}
{{- end }}
{{- end }}
{{ define "slack.title" -}}
[{{ .Status | toUpper -}}
{{ if eq .Status "firing" }}:{{ .Alerts.Firing | len }}{{- end -}}
] {{ .CommonLabels.alertname }}
{{- end }}
{{ define "slack.text" -}}
{{ template "__alert_severity" . }}
{{ range .Alerts }}
{{- if .Labels.status }}
{{- "\n" -}}
[*状态*] {{ .Labels.status }}
{{- "\n" -}}
{{- end }}
{{- if .Annotations.summary }}
{{- "\n" -}}
[*摘要*] {{ .Annotations.summary }}
{{- "\n" -}}
{{- end }}
{{- if .Annotations.description }}
{{- "\n" -}}
[*描述*] {{ .Annotations.description }}
{{- "\n" -}}
{{- end }}
{{- "\n" -}}
---------------------------------------------------
{{- "\n" -}}
{{- end }}
{{- end }}
{{ define "slack.color" -}}
{{ if eq .Status "firing" -}}
{{ if eq .CommonLabels.severity "warning" -}}
warning
{{- else if eq .CommonLabels.severity "critical" -}}
danger
{{- else -}}
#439FE0
{{- end -}}
{{ else -}}
good
{{- end }}
{{- end }}
变量神马的,是继承自prometheus的告警规则,语法神马的,一看就懂了,没啥可说的。slack.color、slack.title、slack.text三个变量,被alertmanager.yml中引用了。
Alertmanager的详细配置方法,可以参考[文档]。
最后,来配置一组告警规则,在prometheus的rules中创建node.yml:
groups:
- name: 主机状态-监控告警
rules:
- alert: 主机状态
expr: up == 0 # up表示node-exporter的连接指标
for: 1m # 等它一分钟
labels:
status: 致命
annotations:
summary: "{{$labels.instance}}:服务器无响应"
description: "{{$labels.instance}}:服务器超过1分钟无响应"
- alert: CPU使用状况
expr: 100-(avg(irate(node_cpu_seconds_total{mode="idle"}[5m])) by(instance)* 100) > 70 # 表达式中的变量,均为node-exporter导入的指标
for: 1m
labels:
status: 告警
annotations:
summary: "{{$labels.mountpoint}} CPU使用率过高"
description: "{{$labels.mountpoint }} CPU使用大于70%(目前使用:{{$value}}%)"
- alert: 内存使用
expr: 100 -(node_memory_MemTotal_bytes -node_memory_MemFree_bytes+node_memory_Buffers_bytes+node_memory_Cached_bytes ) / node_memory_MemTotal_bytes * 100> 80
for: 1m
labels:
status: 严重告警
annotations:
summary: "{{$labels.mountpoint}} 内存使用率过高"
description: "{{$labels.mountpoint }} 内存使用大于80%(目前使用:{{$value}}%)"
- alert: IO性能
expr: 100-(avg(irate(node_disk_io_time_seconds_total[1m])) by(instance)* 100) < 40
for: 1m
labels:
status: 严重告警
annotations:
summary: "{{$labels.mountpoint}} 流入磁盘IO使用率过高"
description: "{{$labels.mountpoint }} 流入磁盘IO大于60%(目前使用:{{$value}})"
- alert: 网络
expr: ((sum(rate (node_network_receive_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance)) / 100) > 102400
for: 1m
labels:
status: 告警
annotations:
summary: "{{$labels.mountpoint}} 流入网络带宽过大"
description: "{{$labels.mountpoint }}流入网络带宽持续2分钟高于100M. RX带宽使用率{{$value}}"
- alert: 网络
expr: ((sum(rate (node_network_transmit_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance)) / 100) > 102400
for: 1m
labels:
status: 告警
annotations:
summary: "{{$labels.mountpoint}} 流出网络带宽过大"
description: "{{$labels.mountpoint }}流出网络带宽持续2分钟高于100M. RX带宽使用率{{$value}}"
- alert: TCP会话
expr: node_netstat_Tcp_CurrEstab > 1000
for: 1m
labels:
status: 告警
annotations:
summary: "{{$labels.mountpoint}} TCP_ESTABLISHED过高"
description: "{{$labels.mountpoint }} TCP_ESTABLISHED大于1000%(目前使用:{{$value}}%)"
- alert: 磁盘容量
expr: 100-(node_filesystem_free_bytes{fstype=~"ext4|xfs"}/node_filesystem_size_bytes {fstype=~"ext4|xfs"}*100) > 80
for: 1m
labels:
status: 严重告警
annotations:
summary: "{{$labels.mountpoint}} 磁盘分区使用率过高"
description: "{{$labels.mountpoint }} 磁盘分区使用大于80%(目前使用:{{$value}}%)"
规则,可以根据prometheus导入的指标写,写成什么样都可以。更新prometheus服务,把rules加入:
prometheus:
image: prom/prometheus:latest
volumes:
- /data/shared/env/tencent-cloud/swarm/prod/etc/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml
- /data/shared/env/tencent-cloud/swarm/prod/etc/prometheus/rules:/rules # 添加这一行
- /data/herewe/prometheus/data:/prometheus
修改prometheus.yml,添加:
alerting:
alertmanagers: # 配置alertmanager
- static_configs:
- targets: ["env_alertmanager:9093"]
rule_files:
- "/rules/*.yml" # 规则在这里
创建目录,数据目录的所有者和prometheus一样,也是65534:65534,更新stack:
可以访问一下看看:
当前是没有活动告警的。这个时候,我们可以在prometheus的Alerts标签中,看到前面我们创建好的告警规则:
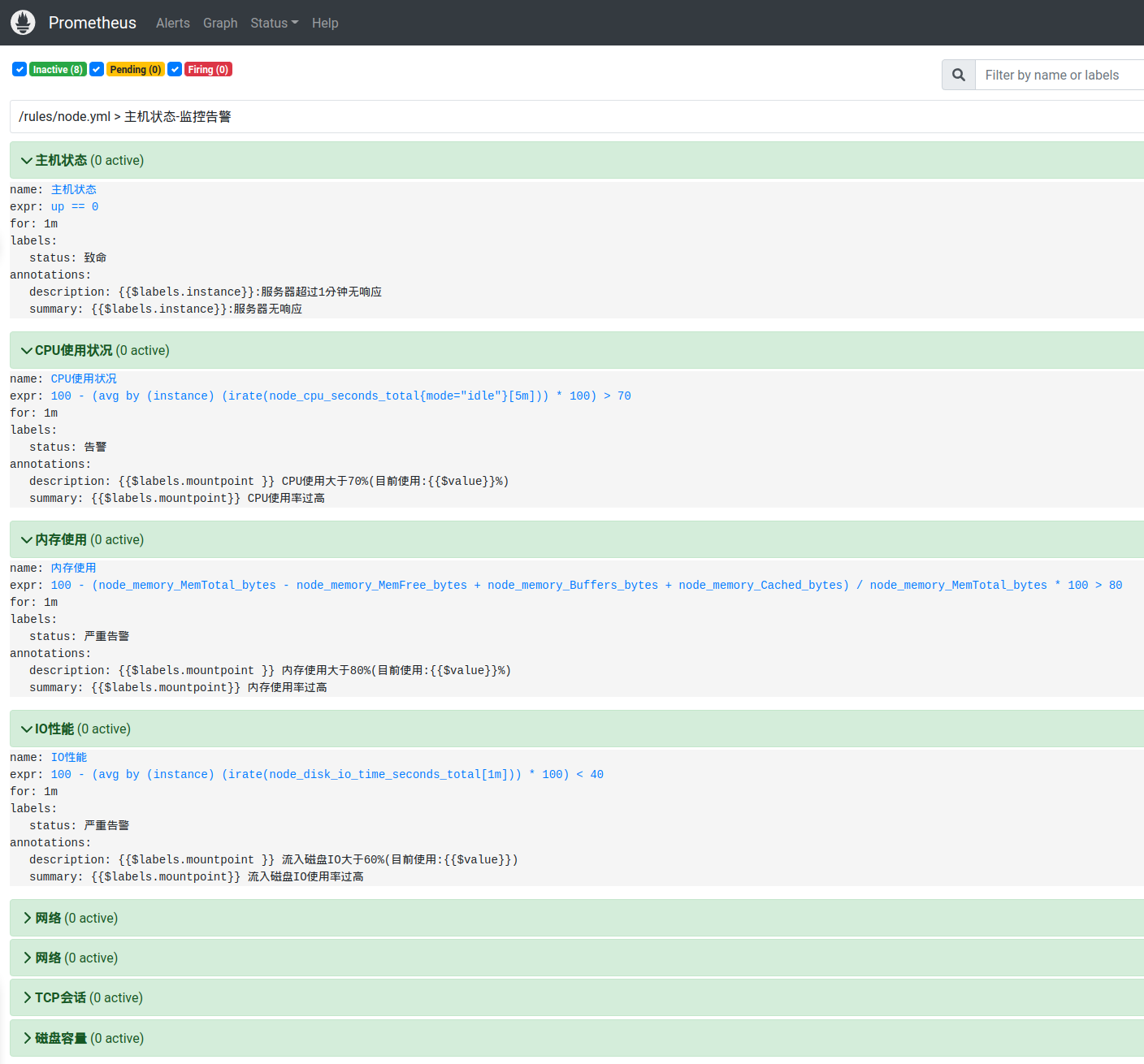
在Status => Rules中也有对应的规则触发状态。
测试告警
接着,可以测试一下告警是否生效。可以尝试触发规则,比如,杀掉一个node-exporter,或者让其不可访问,比如用防火墙挡住prometheus从中拉取指标数据,这里,我们尝试禁止访问q02的9100端口,等待一分钟:
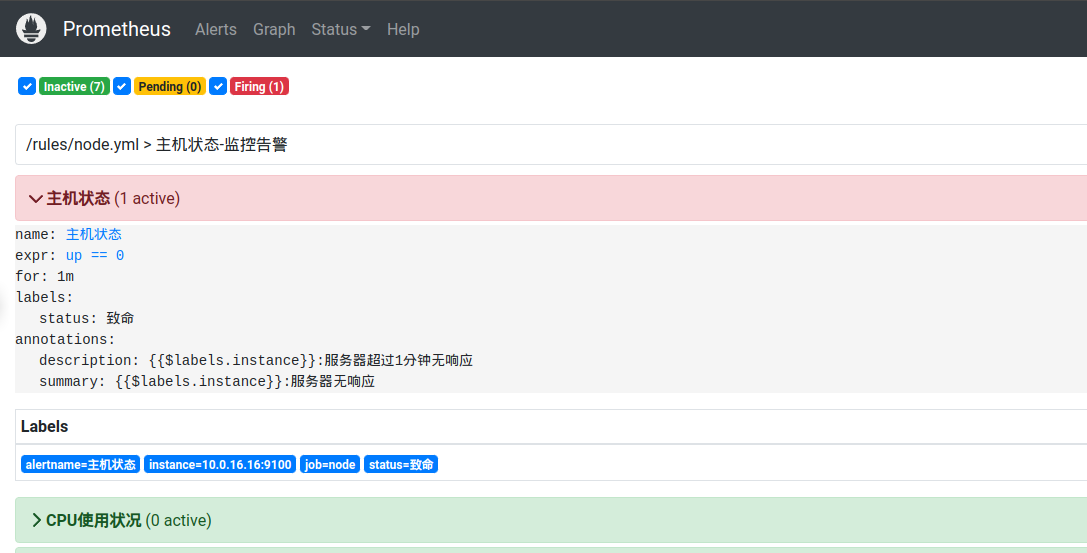
Prometheus中的主机状态这条规则,已经触发了,状态是FIRING,在slack的#ops频道中会收到告警信息,信息是由slack.tmpl模板渲染出来的:
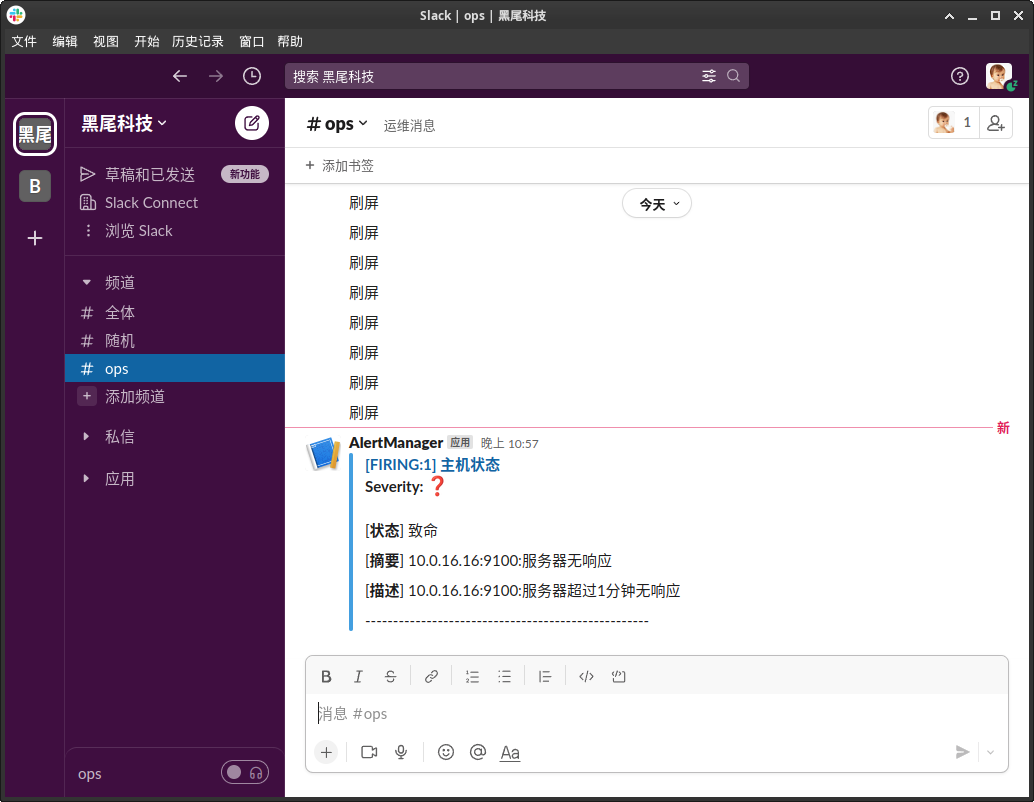
如果配置的是企业微信,就会在企业微信中收到渲染消息,如果配置了邮件,就会收到邮件。通常,在那些有格调的公司,运维告警都会在IM通知的同时伴随短信,因为我暂时没有给短信平台充钱,所以这次就不去演示怎么通过webhook发短信了。在github上可以找到一大堆的实现。
重新让q02的9100可访问,等一小会,规则又变成绿色的了,告警取消了。
我已经写了很长很长很长的一大堆了。如果你有耐心看到这里,估计差不多已经可以把这套看着很复杂其实相对比较省心的环境了解得差不多了。下面我要真正地往上面部署应用了。
Drone —— 很讨喜的CI

Drone是一个轻型的CI工具,很适合我这种需要“低内耗”的场景。但是,我并不打算在本篇里特别细致地介绍它,以后有时间,可能会在别的文章里多写一点。如果你想多了解它一点,可以看看[官网]和[文档]。
Drone支持一些常见的repo源,包括:
Drone支持
- Github
- Gitlab
- Gitee
- Gogs
- Gitea
- Bitbucket
曾经drone还支持coding.net来着,不知道为啥,后面放弃支持了。
由于我的环境在中国大陆,github也许通讯不会那么顺畅,所以下面我用gitee来演示一个go项目的CI流程。
首先在gitee上创建一个第三方应用,填写上你的drone服务主页和回调,回调就填[主页]/login即可,权限勾选projects、pull_requests、notes和hook:
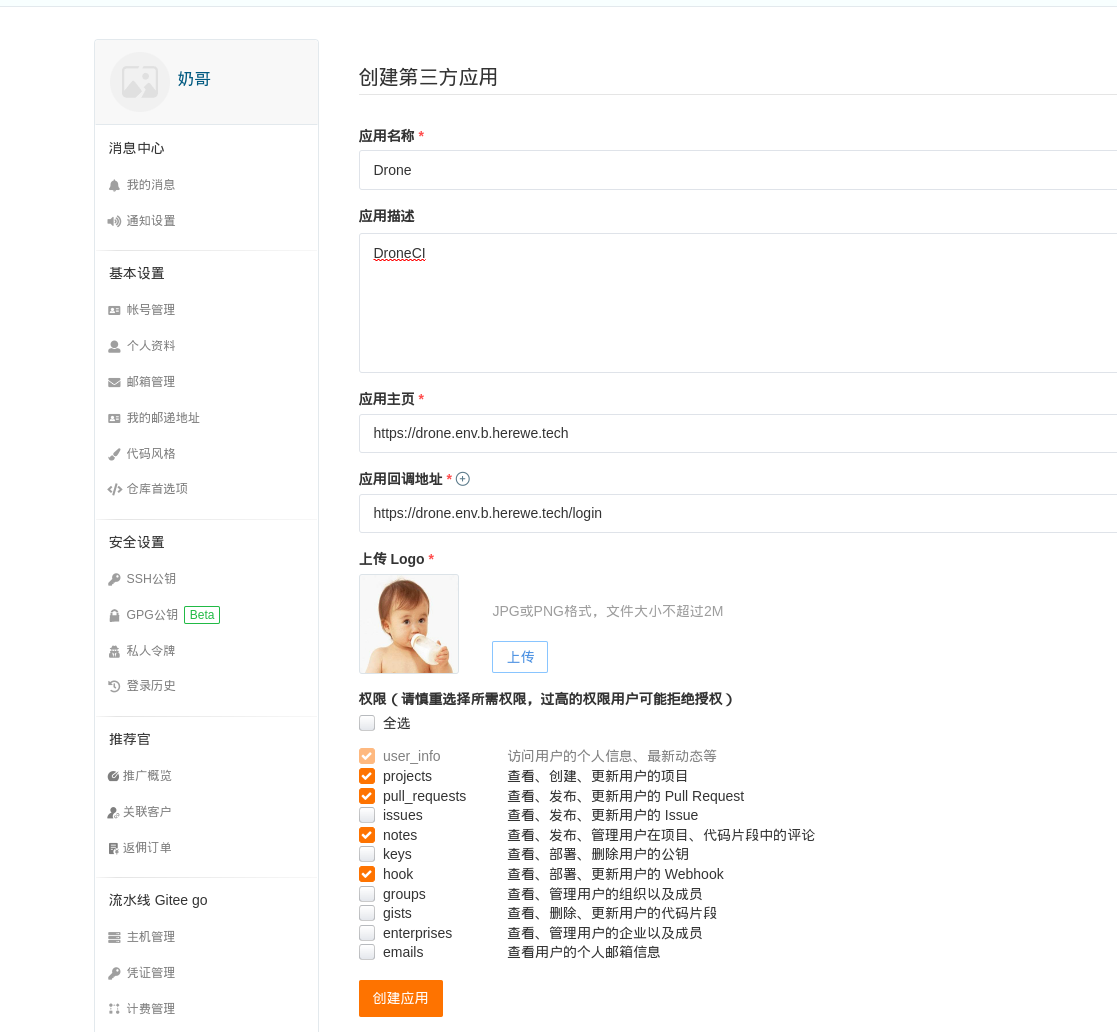
创建成功后,返回一对ClientID和Secret,记住它们,留着下面用。
创建一个新的stack compose,假设就叫drone.yaml:
version: "3.8"
services:
# Drone
server:
image: drone/drone:latest
volumes:
- /data/herewe/drone/data:/data
networks:
- herewe-net
environment:
DRONE_USER_CREATE: username:np,admin:true # 把用户np创建为管理员
DRONE_GITEE_CLIENT_ID: [CLIENT_ID] # 前面在gitee创建的三方应用的ClientID
DRONE_GITEE_CLIENT_SECRET: [CLIENT_SECRET] # 前面在gitee创建的三方应用的ClientSecret
DRONE_SERVER_HOST: drone.env.b.herewe.tech
DRONE_SERVER_PROTO: https
DRONE_RPC_SECRET: dfe00aa5d09bccb460fc7f2138528eb1 # 用来增加与runner之间的RPC通讯安全的加密字符串,随机生成一个就好
deploy:
mode: global
placement:
constraints:
- node.labels.env == main
update_config:
parallelism: 1
delay: 2s
restart_policy:
condition: on-failure
labels:
- "traefik.enable=true"
- "traefik.http.services.drone.loadbalancer.server.port=80"
- "traefik.http.routers.drone.rule=Host(`drone.env.b.herewe.tech`)"
- "traefik.http.routers.drone.entrypoints=websecure"
- "traefik.http.routers.drone.tls.certresolver=le"
# Redirect
- "traefik.http.routers.drone-http.rule=Host(`drone.env.b.herewe.tech`)"
- "traefik.http.routers.drone-http.entrypoints=web"
- "traefik.http.routers.drone-http.middlewares=drone-redirectscheme"
- "traefik.http.middlewares.drone-redirectscheme.redirectscheme.scheme=https"
- "traefik.http.middlewares.drone-redirectscheme.redirectscheme.permanent=true"
networks:
herewe-net:
external: true
更新compose,启动stack,尝试访问:
docker stack deploy --compose-file [drone.yaml文件位置] drone

Continue后会跳转到gitee需要应用授权:
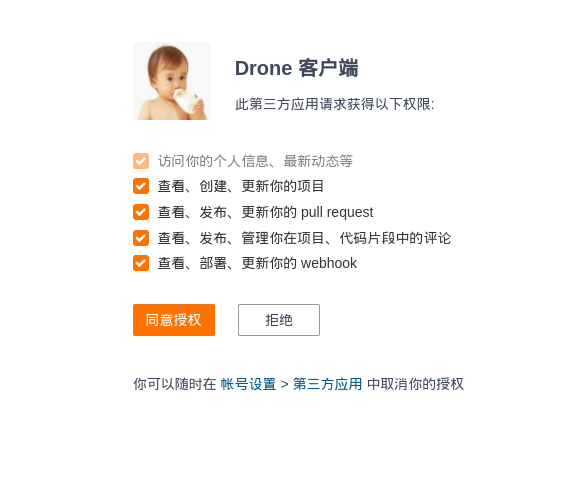
授权后,需要填写一些简单的信息,包括邮箱、组织名、个人名字。如果gitee的授权者用户名和compose中的DRONE_USER_CREATE一致,那么这个用户就会被创建成drone的管理员。全部设置成功后,drone会拉取登录用户在gitee上的所有可读的repo列表,我的就有一大堆:
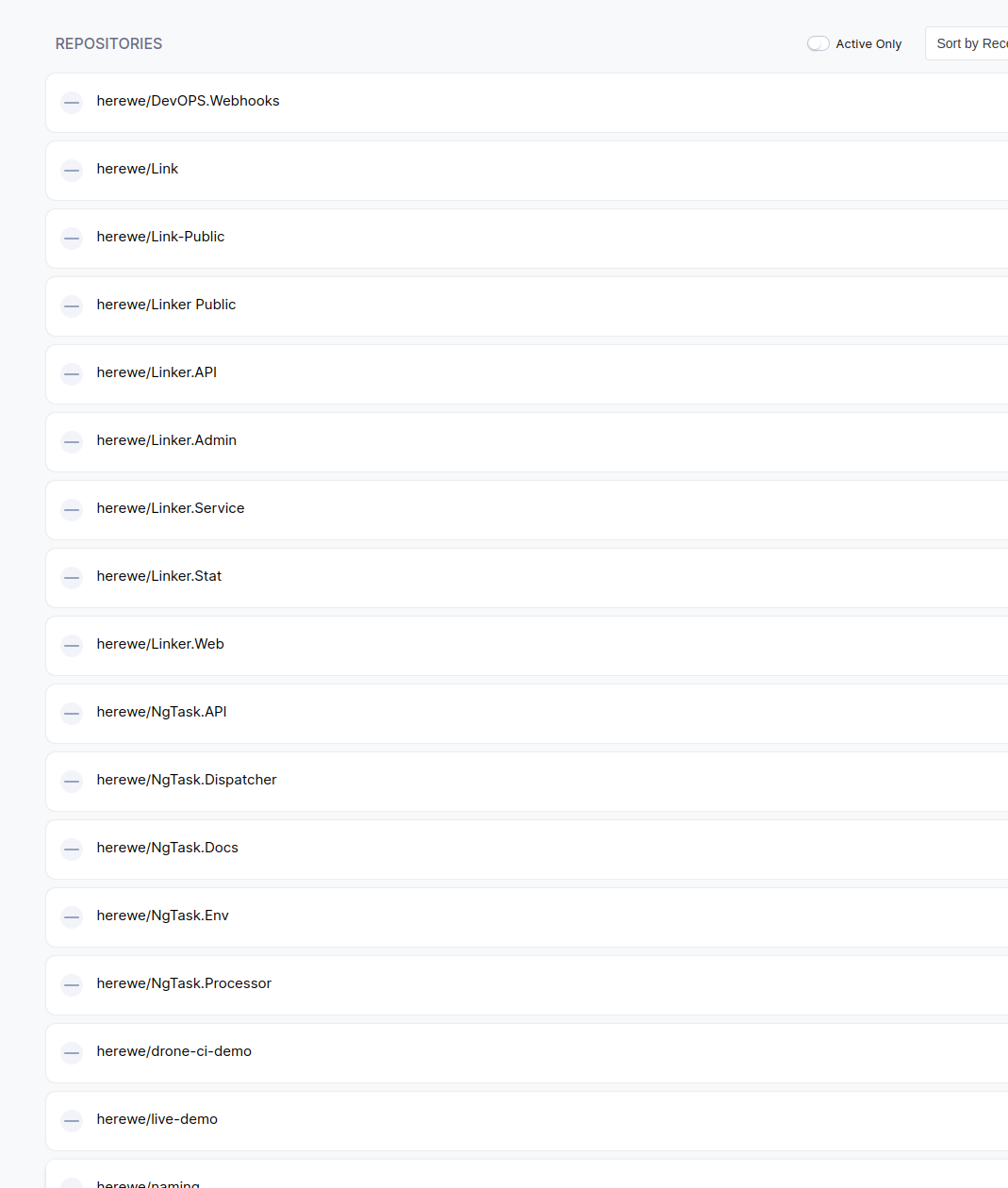
找到需要创建CI流程的那个,active它:
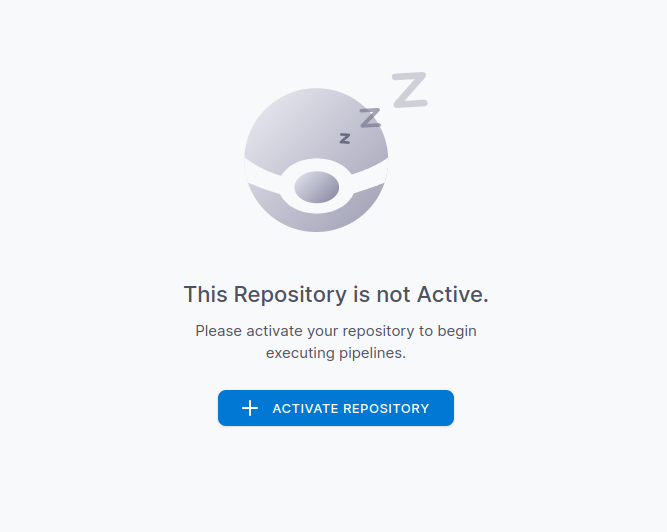
所谓激活,就是在原repo的设置中,自动创建了一个webhook,用于触发CI流水线。在gitee中,我们可以看到刚刚创建的webhook:
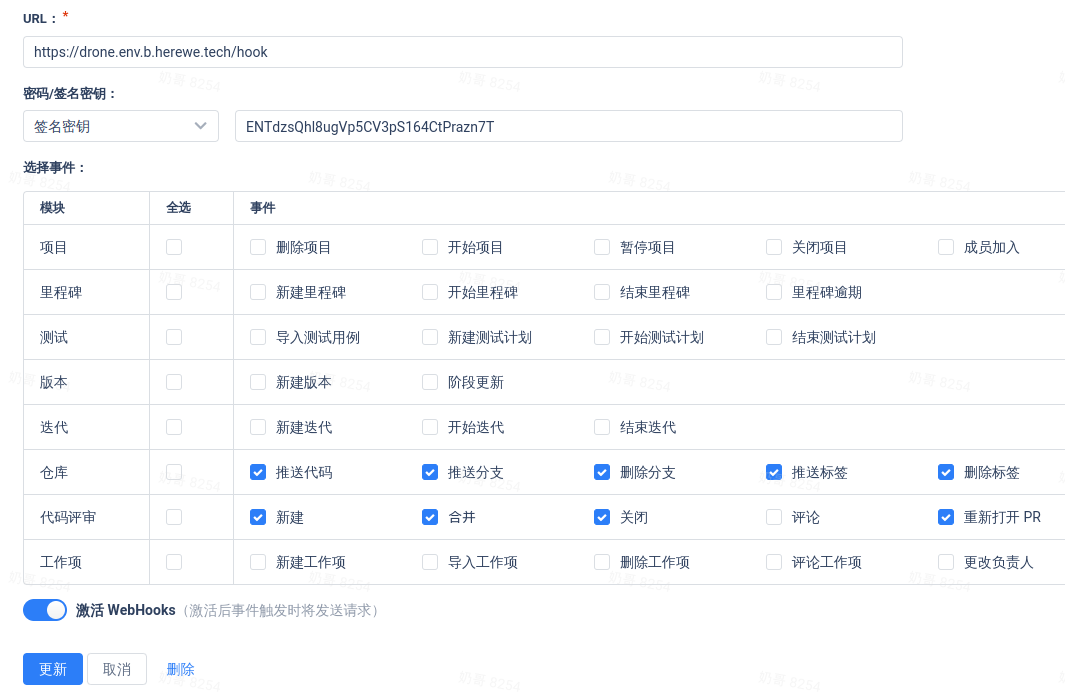
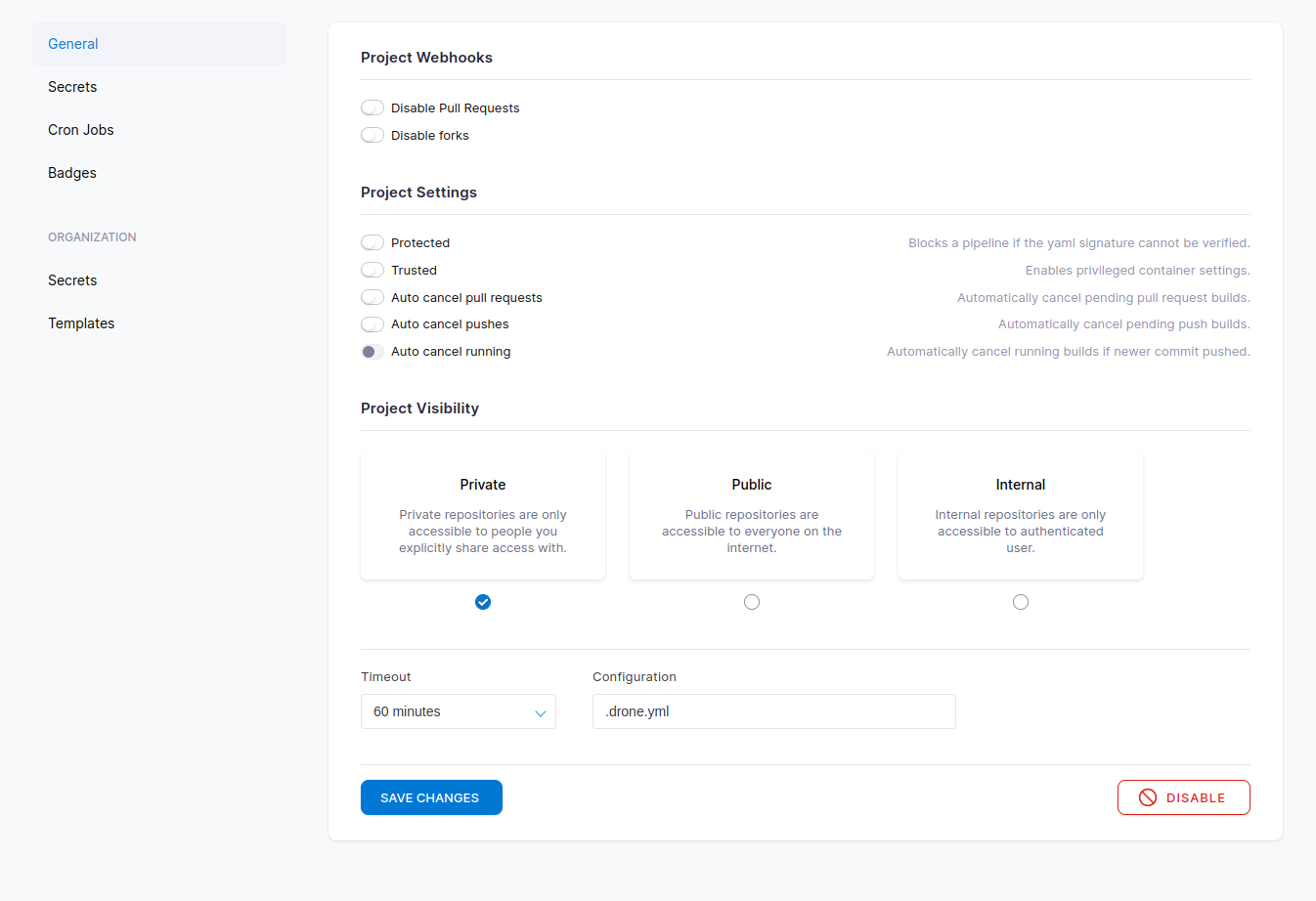
Drone server已经算是成功了。上面只是简单地启动了一个可用服务,使用的是sqlite数据库。Drone在生产环境中推荐使用postgresql,具体可以看文档。
然后,我们需要一个runner来运行pipeline,下面我们会创建docker类型的pipeline,所以,我们在compose中添加drone-runner-docker:
runner-docker:
image: drone/drone-runner-docker:latest
depends_on:
- server
volumes:
- /var/run/docker.sock:/var/run/docker.sock:rw # 需要docker sock来触发
networks:
- herewe-net
environment:
DRONE_RPC_PROTO: http
DRONE_RPC_SECRET: dfe00aa5d09bccb460fc7f2138528eb1 # RPC加密串,需要和server中填写的一致
DRONE_RPC_HOST: drone_server # server服务名
DRONE_RUNNER_NAME: local-docker # runner名字
DRONE_RUNNER_CAPACITY: 2 # 最大并发流水线数,根据所在节点的资源情况调整
DRONE_UI_USERNAME: herewe # UI dashboard用户名
DRONE_UI_PASSWORD: {PASSWORD} # UI dashboard密码
deploy:
mode: global
placement:
constraints:
- node.labels.env == main
update_config:
parallelism: 1
delay: 2s
restart_policy:
condition: on-failure
labels:
- "traefik.enable=true"
- "traefik.http.services.runner-docker.loadbalancer.server.port=3000"
- "traefik.http.routers.runner-docker.rule=Host(`docker.drone.env.b.herewe.tech`)"
- "traefik.http.routers.runner-docker.entrypoints=websecure"
- "traefik.http.routers.runner-docker.tls.certresolver=le"
# Redirect
- "traefik.http.routers.runner-docker-http.rule=Host(`docker.drone.env.b.herewe.tech`)"
- "traefik.http.routers.runner-docker-http.entrypoints=web"
- "traefik.http.routers.runner-docker-http.middlewares=runner-docker-redirectscheme"
- "traefik.http.middlewares.runner-docker-redirectscheme.redirectscheme.scheme=https"
- "traefik.http.middlewares.runner-docker-redirectscheme.redirectscheme.permanent=true"
启动它,可以看到runner的dashboard:
创建一个go项目,设计一下咱的流水线:
- 把指定状态的代码拉回来
- go build一下它
- 把生成的二进制文件打到docker镜像里去
- 把镜像推到私有的registry去
- 控制咱的swarm,用私有registry中的镜像启动服务,在CVM上创建多个容器副本
- 让traefik发现它并正确路由
- 在q02和q03上使用dns负载均衡充分利用一下LightingHouse的出口带宽
- 内部再做一次由swarm控制的负载均衡
随便给这个项目写点功能,比如,访问HTTP服务,输出机器名。main.go:
package main
import (
"fmt"
"log"
"net/http"
"os"
)
func who(w http.ResponseWriter, req *http.Request) {
name, err := os.Hostname()
if err != nil {
fmt.Fprint(w, "Unknown host name")
return
}
fmt.Fprint(w, name)
}
func main() {
http.HandleFunc("/", who)
log.Fatal(http.ListenAndServe(":8888", nil))
}
go.mod:
module whoru
go 1.19
创建Dockerfile:
FROM alpine:latest
ADD whoru /opt/bin/whoru
EXPOSE 8888
CMD [ "/opt/bin/whoru" ]
在项目根目录中创建.drone.yml(注意,最前面有个点):
kind: pipeline
type: docker # 这是一个docker流水线,会触发runner-docker来执行它
name: drone-ci-demo # 流水线名字,会显示在dashboard中
steps:
- name: build # 第一个step,名字是build。一个pipeline中的多个step是顺序执行的
image: golang:alpine # 执行这个step所依赖的docker image
commands:
- "go build ." # 在golang:alpine中编译这个项目
- name: docker
image: plugins/docker:latest # 这个插件用来打包docker镜像并推送到registry
settings:
username: # registry的用户名
from_secret: docker_registry_username # 用from_secret来读取drone中定义的变量,避免将敏感信息直接暴露在代码中
password: # registry的密码
from_secret: docker_registry_password
repo: ccr.ccs.tencentyun.com/herewe/whoru # 不在dockerhub中的镜像要写完整repo
tags: latest # tag
registry: ccr.ccs.tencentyun.com # 嫖用一下腾讯云免费的个人registry
- name: deploy
image: appleboy/drone-ssh:latest # 这个插件用来执行远程ssh命令
settings:
host: # ssh主机名,可以写多个
- 101.43.14.2
username: # ssh用户名,注意这个用户需要成功登录过docker registry
from_secret: swarm_manager_ssh_username
password:
from_secret: swarm_manager_ssh_password
port: 22
command_timeout: 5m # 执行远程命令的最长时间
script: # 执行语句,可以有多条,顺序执行。这里deploy一下stack,每次deploy会检查镜像是否变更了tag到新的hash上,以此实现线上更新的目的
- "docker stack deploy --with-registry-auth --compose-file /data/shared/env/tencent-cloud/swarm/prod/compose/demo.yaml demo"
最后,在swarm中创建一个新的stack,demo.yaml:
version: "3.8"
services:
whoru:
image: ccr.ccs.tencentyun.com/herewe/whoru:latest
networks:
- herewe-net
deploy:
replicas: 6 # 一个怎么够,我要六个!
placement:
constraints:
- node.role == worker # 只想运行在worker上
update_config:
parallelism: 10 # 大家一起更新好了
delay: 2s
restart_policy:
condition: on-failure
labels:
- "traefik.enable=true"
- "traefik.http.services.whoru.loadbalancer.server.port=8888"
- "traefik.http.routers.whoru.rule=Host(`whoru.demo.herewe.tech`)"
- "traefik.http.routers.whoru.entrypoints=websecure"
- "traefik.http.routers.whoru.tls.certresolver=le"
# Redirect
- "traefik.http.routers.whoru-http.rule=Host(`whoru.demo.herewe.tech`)"
- "traefik.http.routers.whoru-http.entrypoints=web"
- "traefik.http.routers.whoru-http.middlewares=whoru-redirectscheme"
- "traefik.http.middlewares.whoru-redirectscheme.redirectscheme.scheme=https"
- "traefik.http.middlewares.whoru-redirectscheme.redirectscheme.permanent=true"
networks:
herewe-net:
external: true
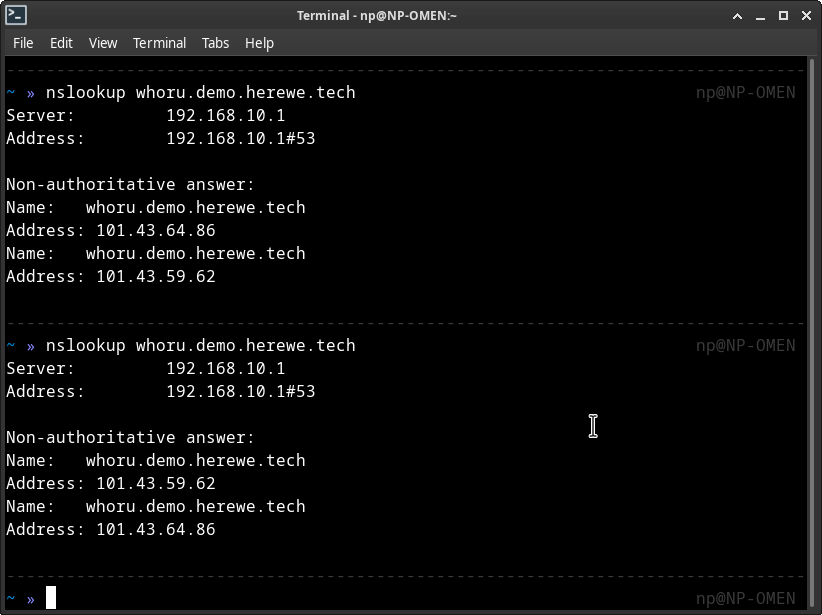
这里进行了一个很骚的骚操作:whoru这个服务对外的域名,同时解析到了q02和q03的公网IP上,每个IP的权重都是50,由于q02和q03上都有traefik服务,所以,借用dns实现了第一层的负载均衡:
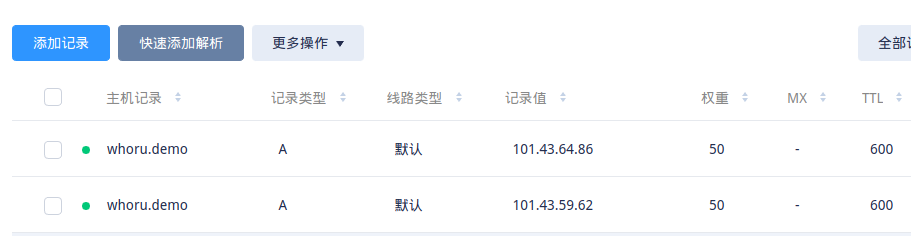
由于dnspod免费版的解析服务,每个域名只能添加两条A记录解析,所以就添加了两个50%。本次实验的目的是降低内耗,当然也包括花钱~
在腾讯云的个人版容器镜像服务中,把前面我们填写的命名空间herewe创建出来。个人版的服务是共享域名的,所以一个地域下的命名空间是唯一的,别人用了你就不能用了。在这个过程中,会初始化登录密码。
然后,一个关键的步骤:在所有必须的节点上都登录一遍,因为它们要靠自己去拉镜像,而不是靠manager同步。由于docker的登录凭证是系统用户之间隔离的,所以A用户登录后的凭证,B用户并不共享。所以,我们切换到drone deploy时,ssh目标服务器使用的用户身份来进行:
docker login ccr.ccs.tencentyun.com
在drone中,填好所有的secret:
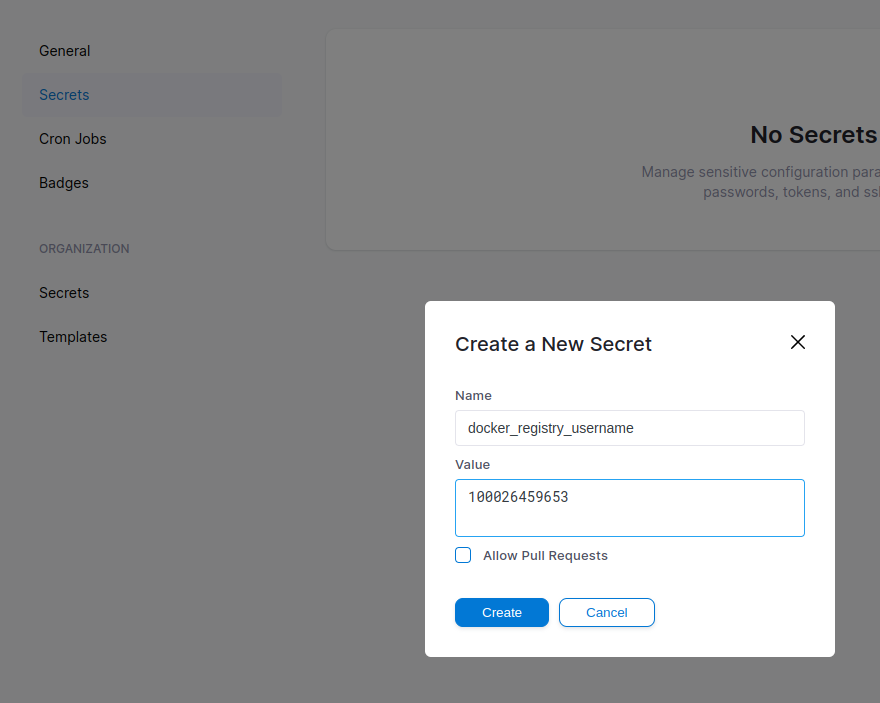
注意这里,上下有两个secret,上面那个是作用于当前repo的,下面那个是组织的,也就是你名下的所有repo。
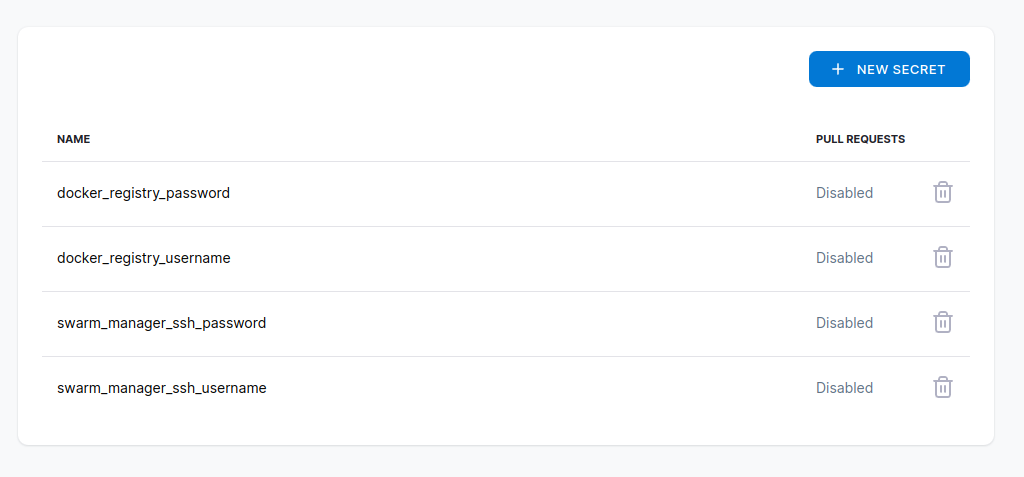
Secret填好之后,在drone的页面上就不能再查看value了,只能做删除操作。
OK,让我们荡起双桨的同时,git push。这时候,如果webhook正常,drone上就会出现一个在执行的pipeline:
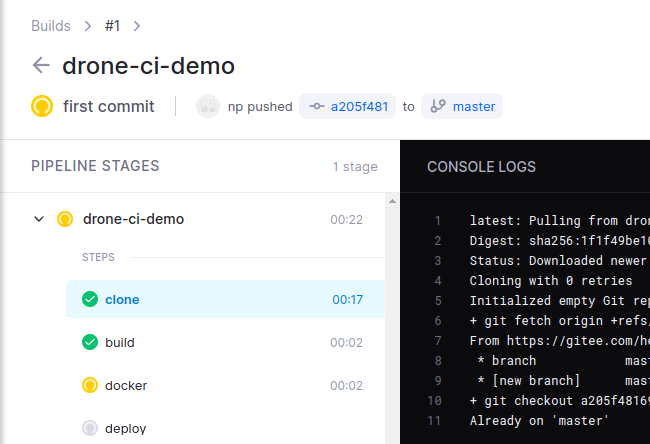
clone是drone的固定流水线起始点,就是拉代码回来。后面的三个,就是我们写在.drone.yml中的三个step,drone会按顺序一个一个执行。执行成功后,GRAPH VIEW里可以看到一个流水线的图所有节点都变绿了:
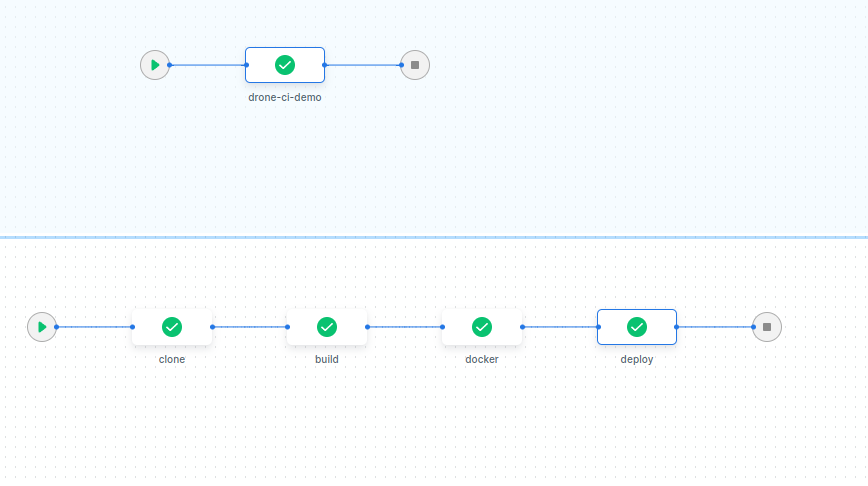
通过manager观察,可以看见demo_whoru这个服务已经起了六个副本,c01、c02、c03上每个节点有两个:

Swarm会根据它自己的判断来把容器起在它认为正确的地方,说你行你就行不行也行的那种。再看看,DNS的骚操作也成功了:
看看咱的成果,玩命地curl它:
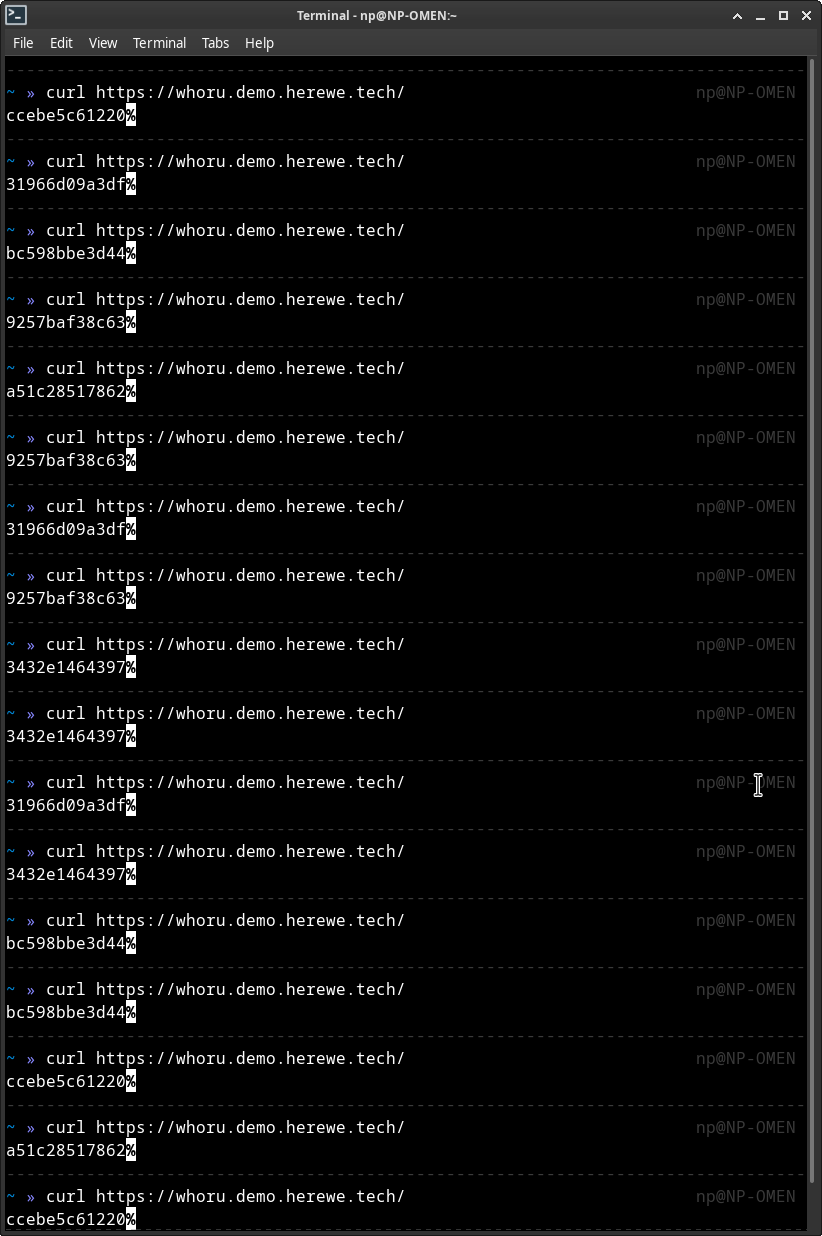
每次q02和q03轮流提供代理,whoru的六个副本轮流提供服务。os.Hostname()在容器中读到的主机名,就是这么一串容器ID,集群内唯一的。
到此,咱的环境和服务完满达到了咱的要求~