Nomad小型集群构建记录
今天来做一个实施,把黑尾盒子的运行环境从docker swarm切换成nomad。之前许下的,得做。
关于nomad的一些介绍,可以看[官网]。nomad本质上是和k8s处于同一生态位的实现,它在中文文档中蹩脚地称为“集群管理和工作负荷调度器”。nomad支持容器、虚拟机及原生可执行程序,本身并不负责服务发现和密钥,而是依赖自家的consul和vault,所以它比较全功能的k8s,还是要轻好多的。
凡事都有第一次,为了nomad在我手里光辉的第一次,我初始化了我的云环境:
- LightingHouse * 3(debian bullseye)
- CVM * 3(debian bullseye)
- Consul * 3
云联网已创建。
安装一下
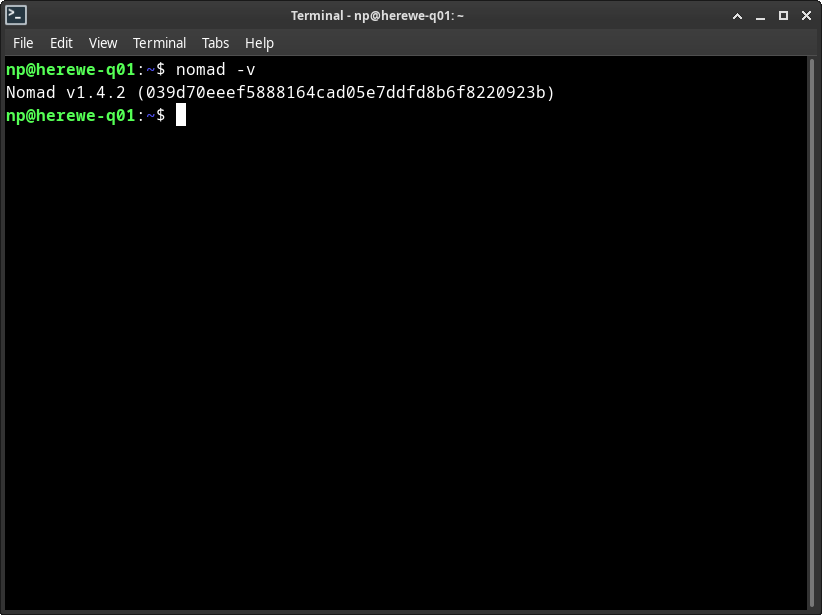
按照[官方文档]在每个节点上装好nomad。Nomad是一个独立的二进制文件,非常简单。
官方的安装文档中在debian系发行版上使用了apt-add-repository,这东西在bullseye的裸服务器版本上默认是没有的,需要安装software-properties-common,然后连带安装一大堆包。如果不想安装这些玩意,手动生成apt配置即可:
echo "deb [arch=amd64] https://apt.releases.hashicorp.com $(lsb_release -cs) main" | sudo tee /etc/apt/sources.list.d/hashicorp.list > /dev/null
然后一路apt操作,安装nomad就好。装好之后,可以验证一下:
然后,咱们从腾讯云的“微服务引擎(TKE)”中,嫖一个consul集群。正常来说,这东西是不会单独使用的,所以在腾讯云上创建一个,并没有单独计费。记得要创建到对应的子网中。这波操作可是太6了:
启用服务,并启动:
sudo systemctl enable nomad
sudo systemctl restart nomad
默认的nomad配置,是同时启动server和client的。这里咱们准备在三个lightinghouse上启动server,并在三个cvm上只启动client,也就是,三个server节点,六个client节点。关注/etc/nomad.d/nomad.hcl,默认的配置只有这么点东西:
# Full configuration options can be found at https://www.nomadproject.io/docs/configuration
data_dir = "/opt/nomad/data"
bind_addr = "0.0.0.0"
server {
# license_path is required as of Nomad v1.1.1+
#license_path = "/opt/nomad/license.hclic"
enabled = true
bootstrap_expect = 1
}
client {
enabled = true
servers = ["127.0.0.1"]
}
改了改了:
datacenter = "tencent-sh"
data_dir = "/opt/nomad/data"
bind_addr = "0.0.0.0"
consul {
address = "[嫖来的consul中的一台IP]:8500"
auth = "nomad"
token = "[嫖来的consul中初始化ACL的token]"
checks_use_advertise = true # 这个一定要写
}
checks_use_advertise = true这个一定要加。这里设置consul在对服务进行健康检查时候,绑定于服务的advertise地址上。这个配置默认是false,会将健康检查进行在第一个HTTP服务上,如果没有,默认回退到server的bind_addr,然而这里我们bind了0.0.0.0,服务虽然在consul上可以注册,但是健康检查会是失败的。
创建/etc/nomad.d/client.hcl,表示激活client:
client {
enabled = true
}
咱们计划就是在六个节点上都执行client,所有六个节点全都enabled了就可以了。
接下来,在三个需要执行server的节点上创建/etc/nomad.d/server.hcl:
server {
enabled = true
bootstrap_expect = 3
}
bootstrap_expect = 3表示这个集群希望有三个server,才能成局。
全都搞好之后,重启nomad服务,观察consul上的服务状态:
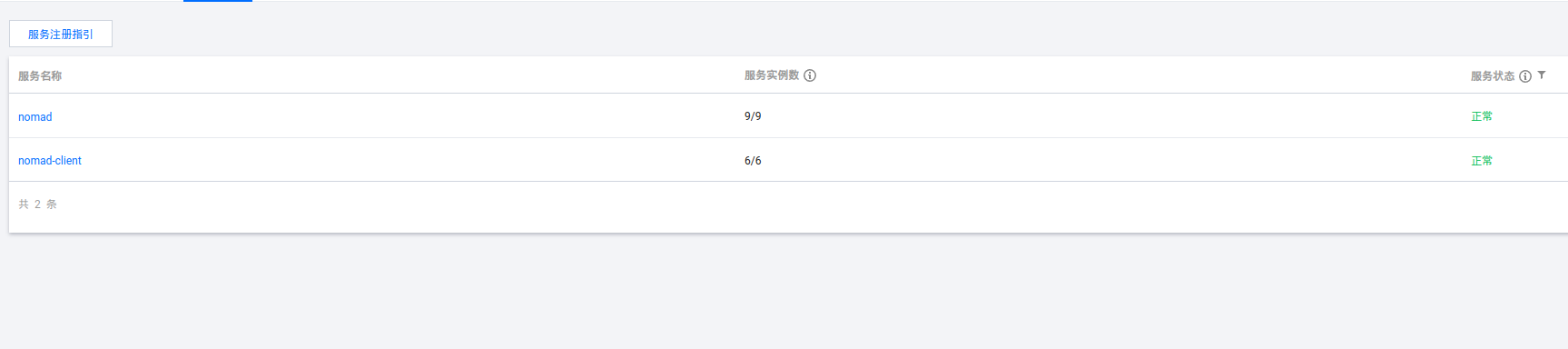
可以看到,server注册了9个服务(每个节点有三个),client注册了6个。看看server中的状态:
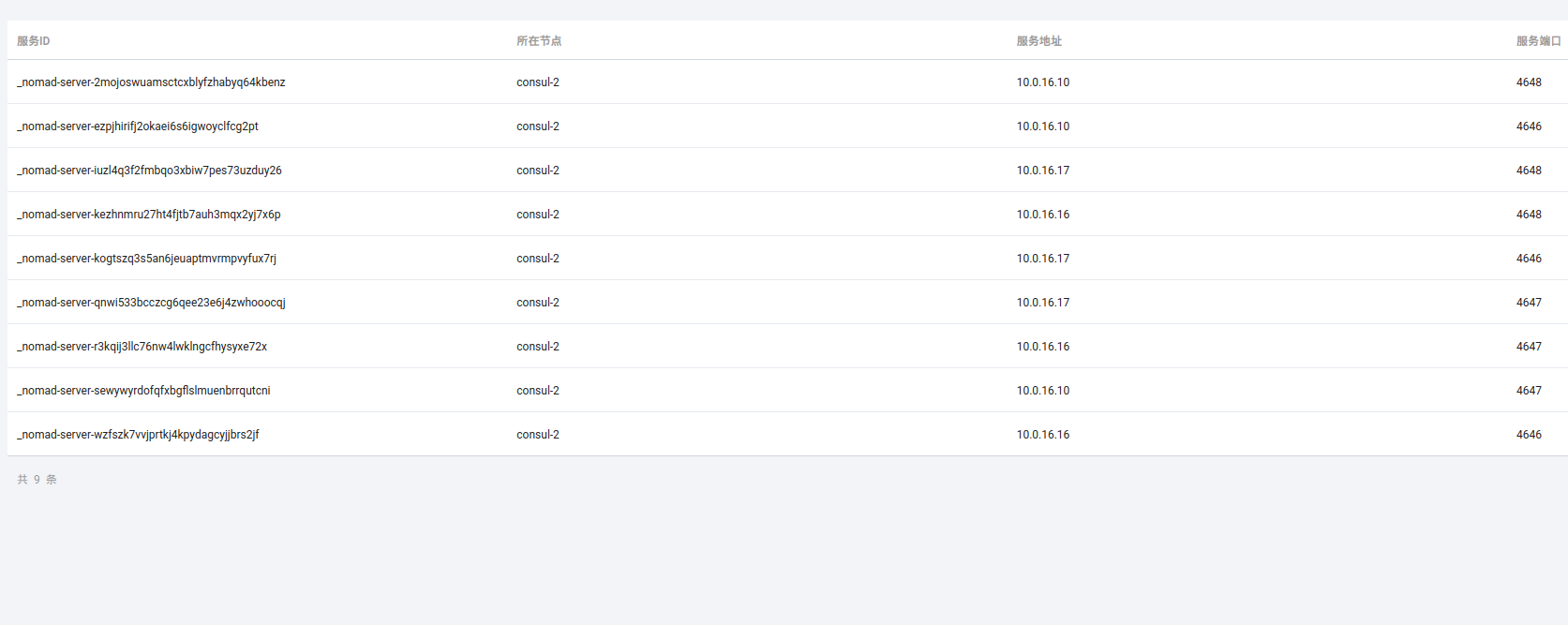
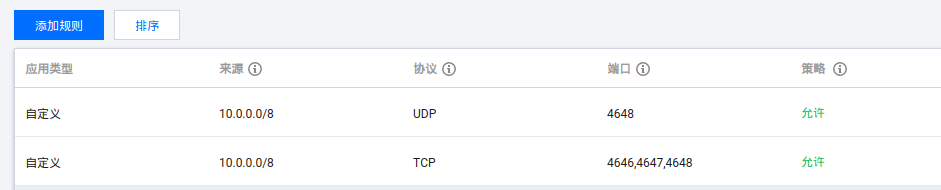
每个节点都注册了4646、4647和4648三个端口。如果注册失败,可以检查一下防火墙:
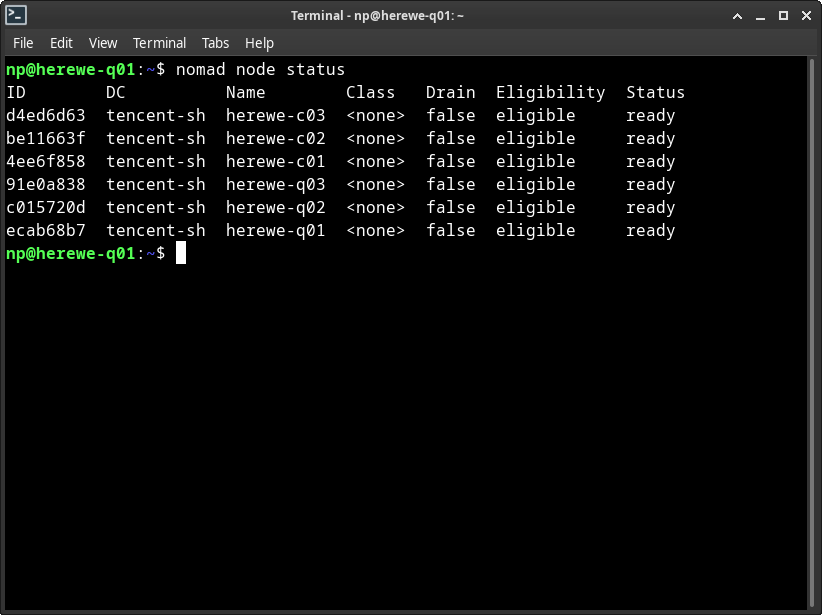
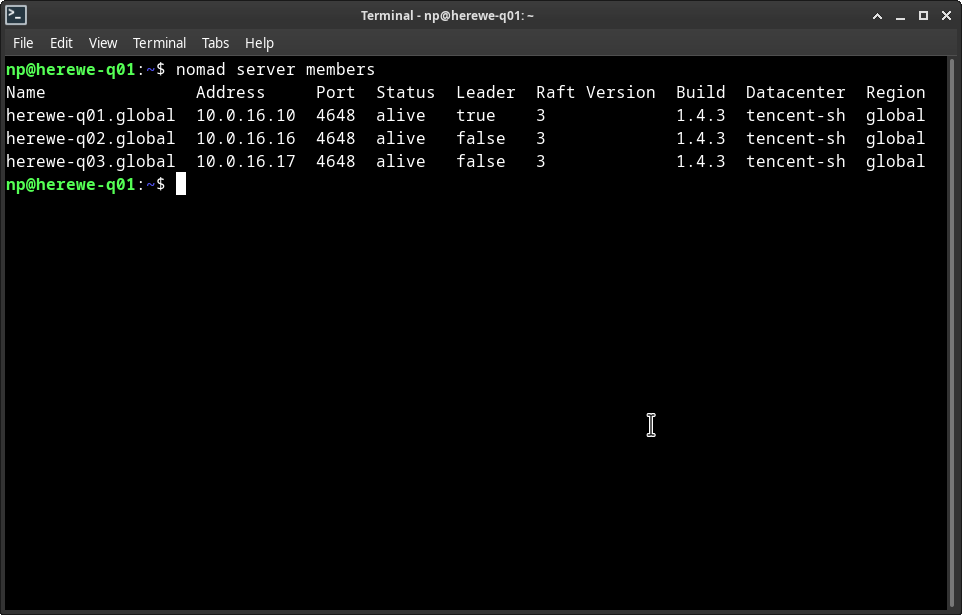
来看看节点状态,随便找一个节点执行就可以,不像swarm只能在manager上查看,nomad在哪里看都可以:
nomad node status
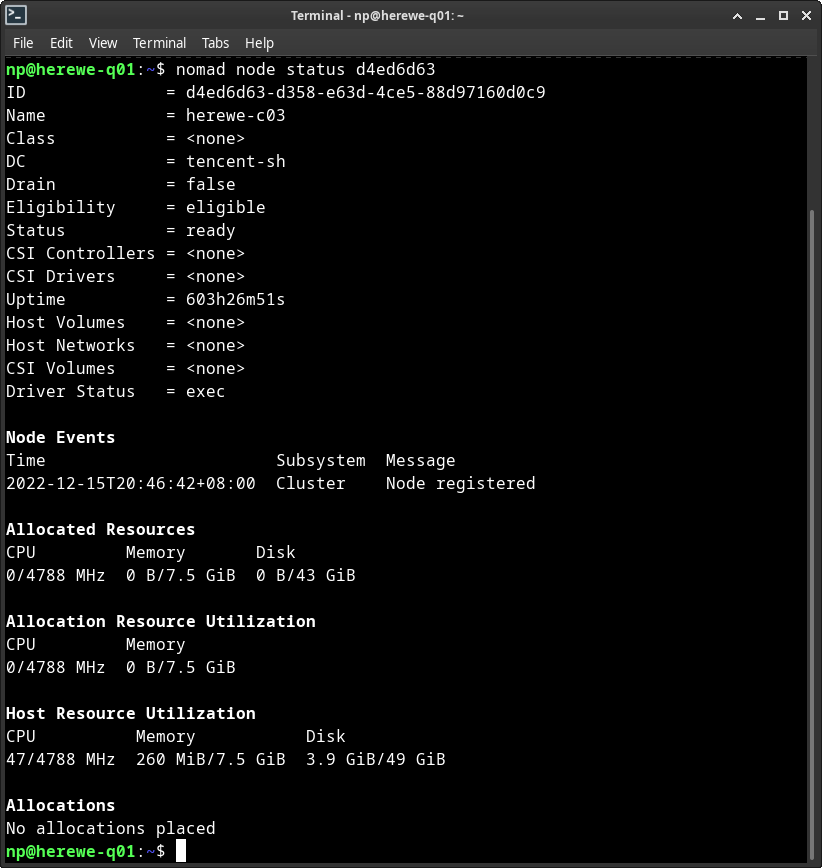
也可以查看其中一个节点:
再看看server:
nomad server members
下面我们就可以开始
应用部署
nomad的部署,粒度级别为:job->group->task->alloc。每个HCL描述文件中描述单一一个job,每个job中可以有多个group,每个group下可以有多个task,每个task执行多个alloc。job对应于swarm中的stack,task对应于service,alloc对应于容器实例。
Swarm中并没有group这个玩意,nomad的group表示task在client上的分组,一个group内的task,运行于同一个client上。
HCL的语法类似于json,可以认为是json的超集,实际上HCL也确实会被解析成json并发送给nomad的HTTP API。
与上一篇的swarm实例类似,咱们起一组env job先。首先创建一个env.hcl,然后定义job:
job "env" {
}
定义第一个名为lb的group,作用是服务对外访问的负载均衡,与swarm上运行traefik类似,所有的HTTP和TCP请求都由lb导入集群中。nomad也可以使用traefik,但是hashicorp自己推荐了一个叫fabio的非常新的东西,也是挺可以的,这次咱们也玩把洋气的,选择fabio做lb:
job "env" {
datacenters = ["tencent-sh"]
type = "system"
group "lb" {
network {
port "lb" {
static = 9999
}
port "ui" {
static = 9998
}
}
task "fabio" {
driver = "podman"
config {
image = "fabiolb/fabio"
network_mode = "host"
ports = ["lb", "ui"]
}
env {
FABIO_REGISTRY_CONSUL_ADDR = "[嫖来的consul中的一台IP]:8500:8500"
FABIO_REGISTRY_CONSUL_TOKEN = "[嫖来的consul中初始化ACL的token]"
}
}
}
}
datacenters定义了,job运行在哪些集群上,咱们只有一个tencent-sh,搞上。
type=system定义了这个job的调度方式。nomad有四种调度方式:
- service - 服务,nomad的默认调度方式,也就是长时运行的守护进程。
- batch - 短时任务,虽说短时,但并没有定义具体的运行时间要求。与service不同,batch在运行完成后就退出了,service在异常结束时会尝试重启。
- system - 系统服务。system job会在所有client节点上执行,即使是在job创建后再加入的集群的节点,也会尝试创建并启动。
- sysbatch - 系统短时任务,与batch类似,sysbatch在运行结束后不会尝试重启,且在新加入集群的节点上会尝试运行一次。
这里的fabio作为lb,咱们希望它随处都在,所以起了个system。
这里的group中,定义了network,所需两个端口,一个是9999,fabio的对外负载均衡的服务端口,一个是9998,fabio的管理HTTP服务,dashboard和health check也在上面。
task定义了一个fabio,注意里面的driver = podman,告知nomad以什么方式执行task。nomad支持多种driver,包括有:
- Docker - docker方式执行task,也是nomad最常用和默认的方式
- Fork/Exec - 执行本地命令,直接执行client本地的程序。分为isolated(隔离)和raw(原生)两种模式
- QEMU - 使用QEMU引导镜像创建虚拟机,支持KVM等qemu支持的各种姿势
- Java - JVM中运行jar
- Podman - podman方式执行task。podman是docker的一种平替方案,与docker不同,podman是没有本地服务的,所以也并没有swarm这些东西,只是一个OCI格式容器的命令行封装,并与docker保持参数级兼容,通常可以直接在系统中alias docker=podman。
咱们这里使用了podman,不图别的,癞蛤蟆x青蛙,长得丑还玩得花。
首先需要在所有节点上安装podman,debian / ubuntu直接apt就行了。装好后,需要做一点点小设置:/etc/containers/registries.conf中,需要修改:
unqualified-search-registries = ["docker.io"]
具体理由可以看上面的一大堆RISK。如果不添加docker.io,podman不会像docker那样,对于tag中不包含域名的image,默认去docker.io上找。所以,或者每次都把image的tag带上仓库地址写完全,或者在这个配置中添加一个docker.io。当然如果想改成别的,比如企业内部的registry,也是没问题的。
这样修改之后,上面HCL中的image:fabiolb/fabio就可以从docker.io上pull回来了。
然后,需要在nomad的配置上添加一个plugin。没错,podman需要plugin支持(直接写在/etc/nomad.d/nomad.hcl中就可以):
plugin "nomad-driver-podman" {
config {
volumes {
enabled = true
}
}
}
这里的nomad-driver-podman是一个go plugin,从[这里]获取,编译(make dev)后放到/opt/nomad/data/plugins中即可。注意go plugin不能用gccgo编译,但是编译这东西需要gcc……
这么费事,所以说玩得花。如果你不想费这个事,改成driver=docker就行了。当然,所有节点上需要安装docker engine。
最后,重启nomad:
systemctl restart nomad
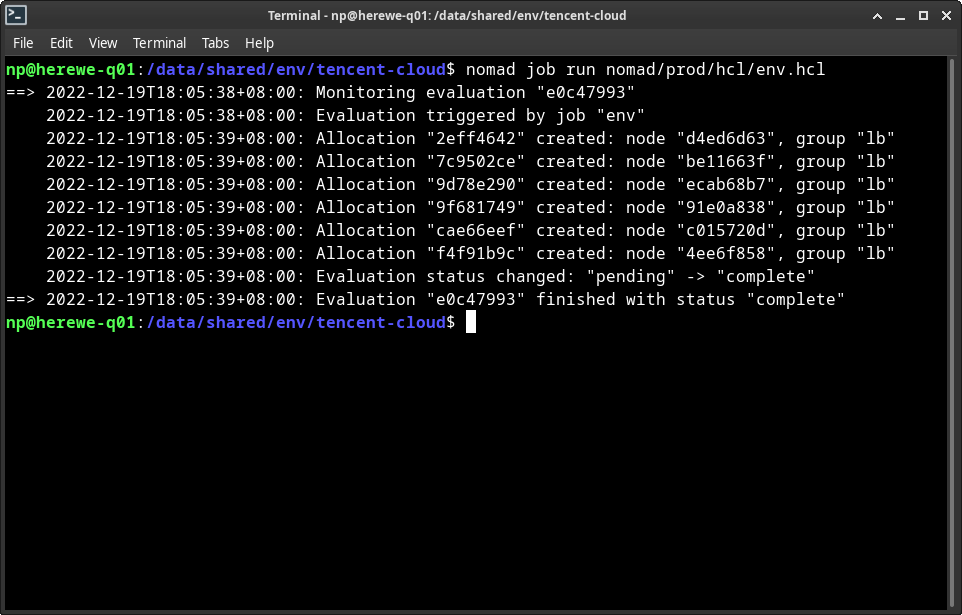
执行这个job:
nomad job run env.hcl
可以查看job的status:
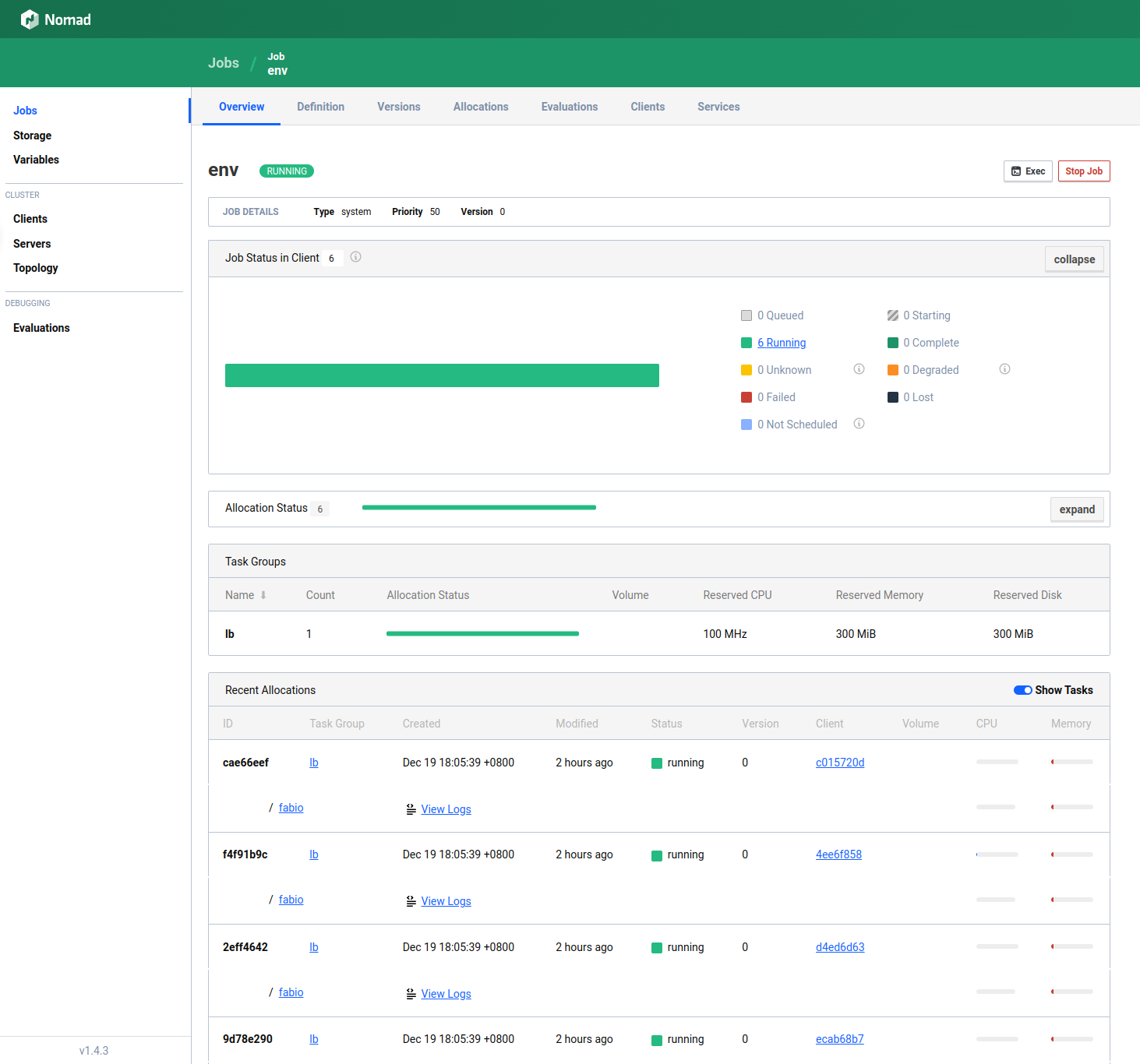
nomad job status env
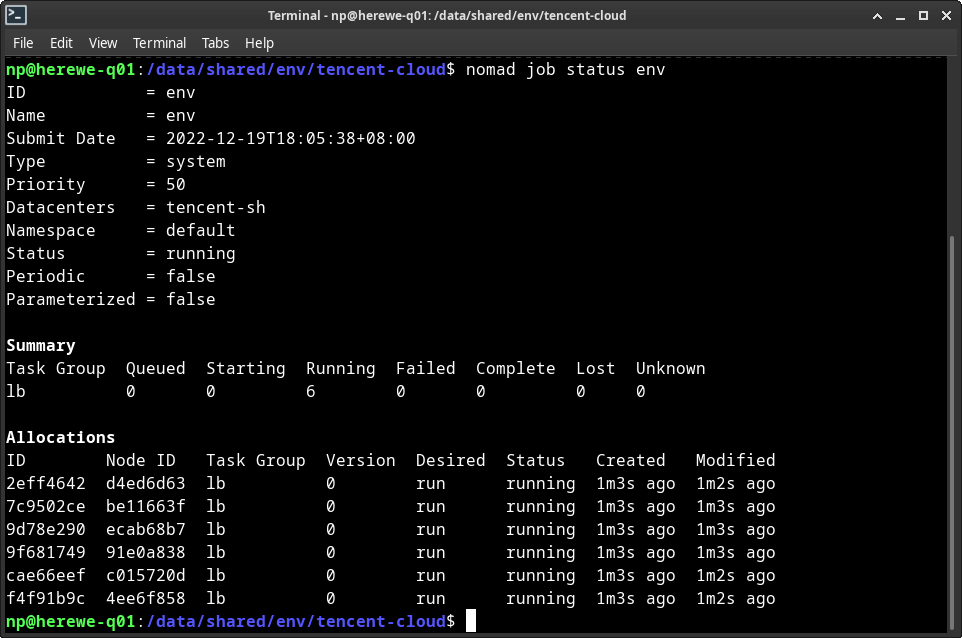
可以看到这个job,创建了一个group,名字叫lb,然后有六个allocations,对应着task的六个实例。alloc也可以查看status:
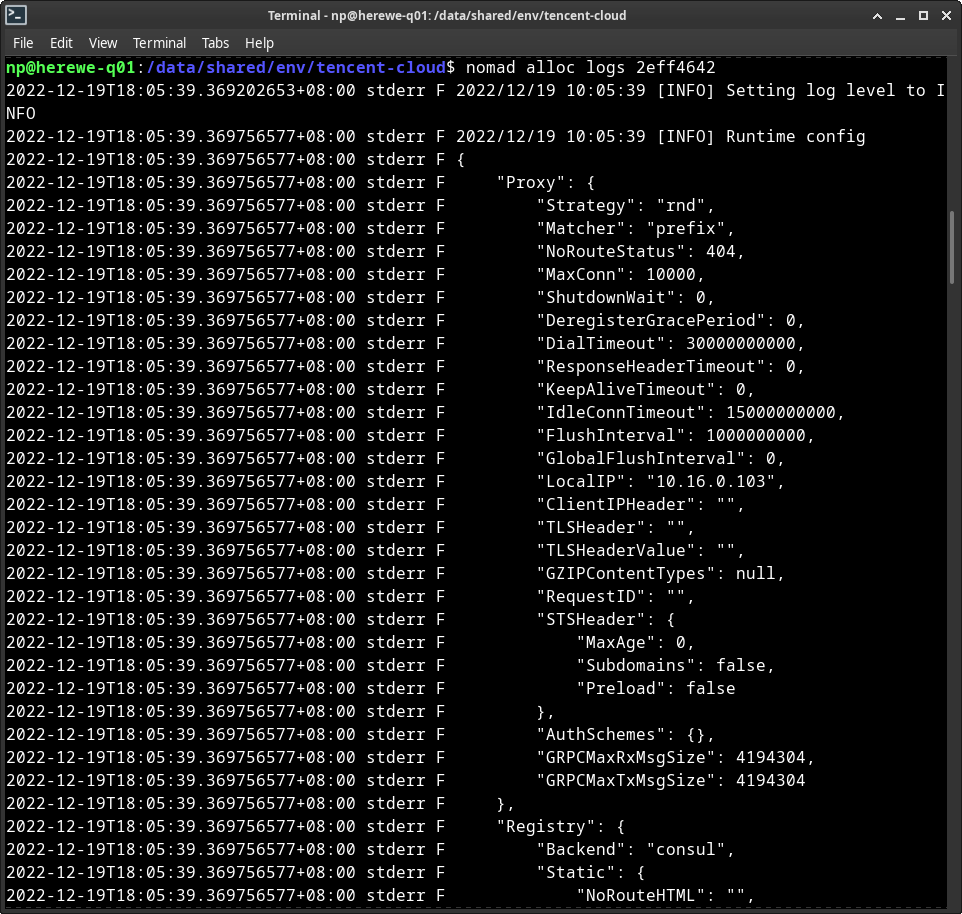
nomad alloc status 2eff4642
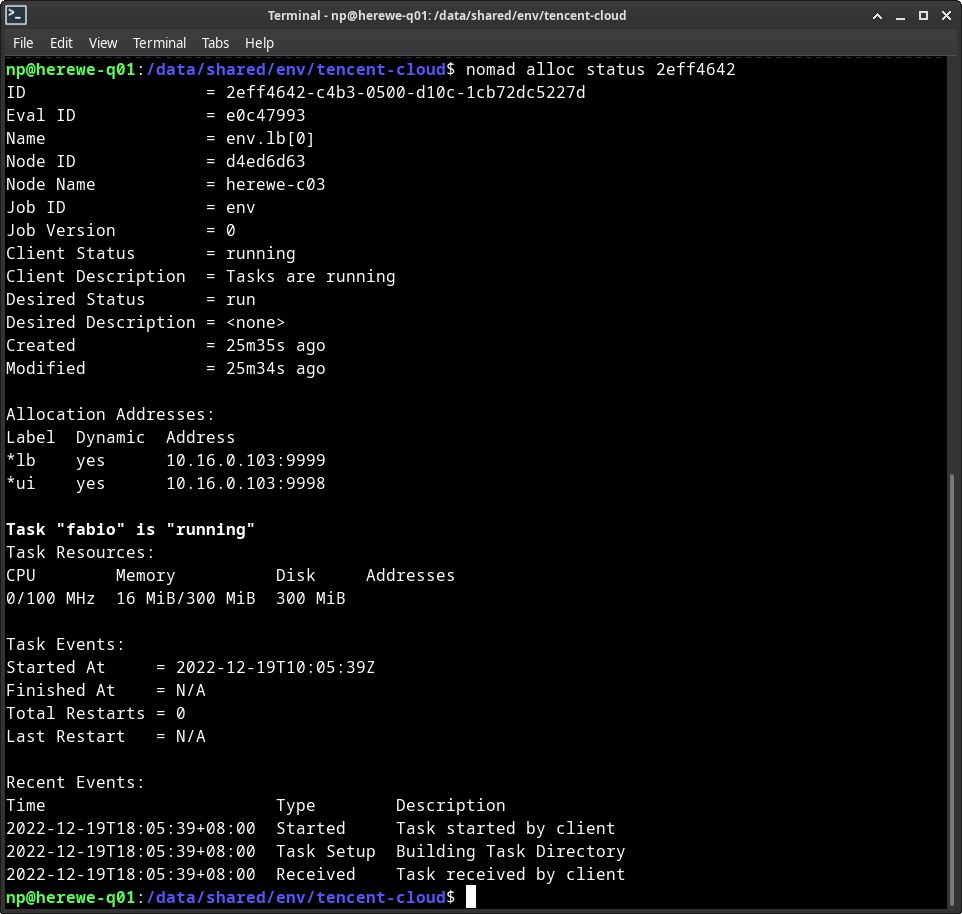
这是一个运行在c03上的实例,初始资源为CPU 100MHz、内存300MB、磁盘300MB。可以查看这个实例的日志:
nomad alloc logs 2eff4642
这个时候,看看consul的服务列表:
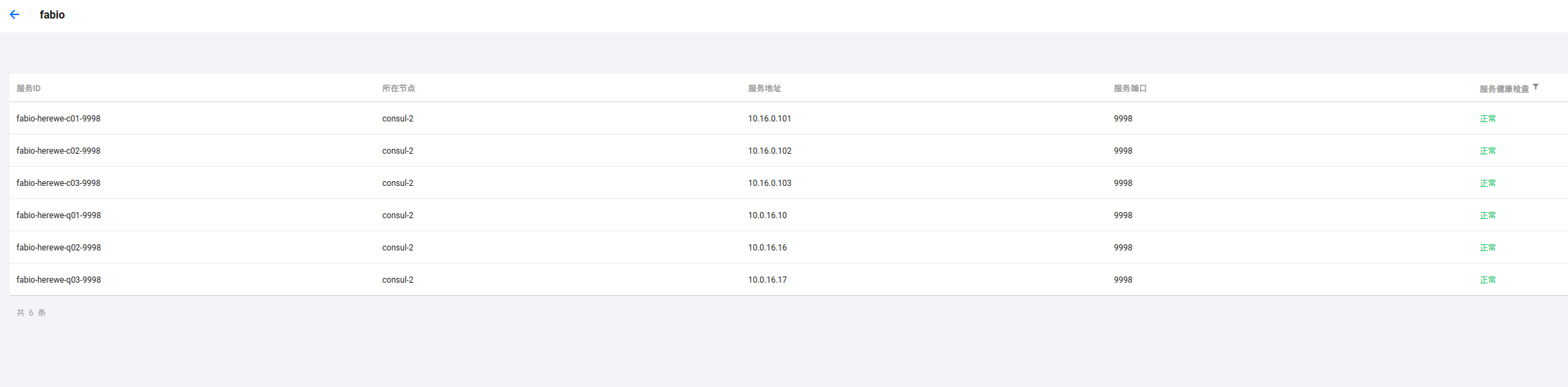
服务fabio的六个实例都注册上了。如果健康检查状态不正常,检查一下防火墙,看看9998端口是不是可以被consul访问到:
下面来验证一下
访问一个节点的4646端口:
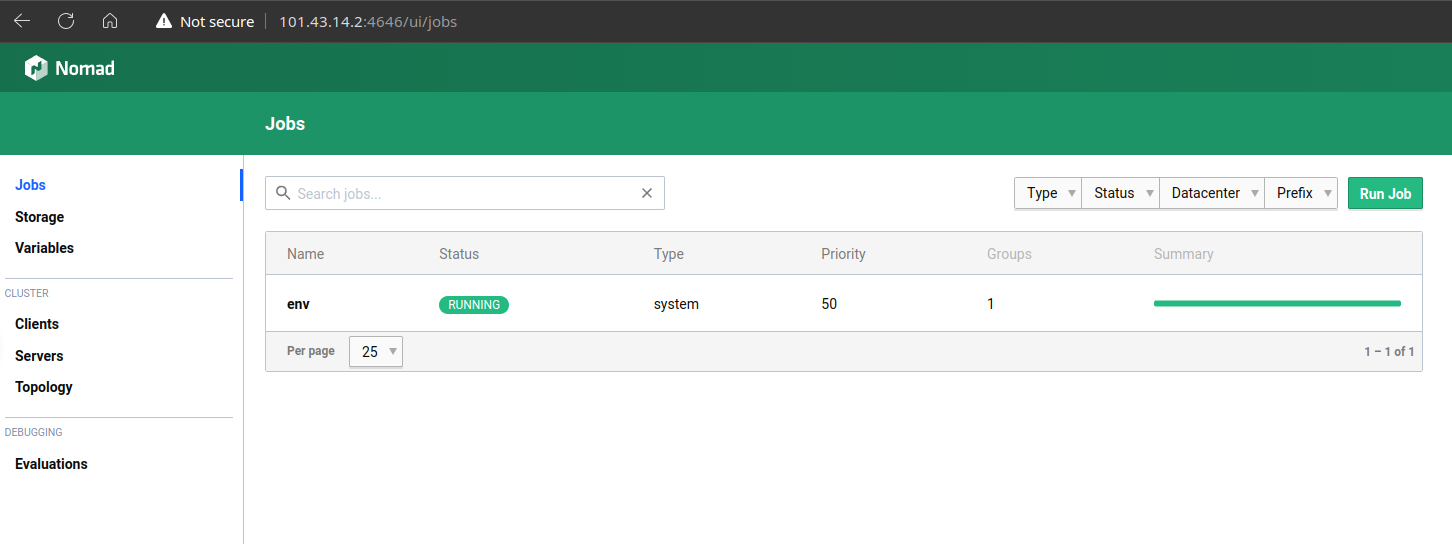
打开job,可以看到若干细节:
访问节点的9998端口,可以看到fabio的dashboard:
为了可以正常提供HTTP服务,咱们需要正确配置fabio的LB,让它可以正常接管HTTP请求。
Fabio
Fabio的默认lb服务地址是:9999,默认支持的协议是HTTP和HTTPS。fabio还支持grpc和TCP,具体可以查看[文档]。下面我们把lb端口改成80和443:
group "lb" {
network {
port "lb-http" {
static = 80
}
port "lb-https" {
static = 443
}
port "ui" {
static = 9998
}
}
task "fabio" {
driver = "podman"
config {
image = "fabiolb/fabio"
network_mode = "host"
ports = ["lb-http", "lb-https", "ui"]
}
env {
FABIO_PROXY_ADDR = ":80,:443"
}
}
}
这个时候,fabio就会监听80和443端口了,但是这个时候443并不是SSL,只是个普通的HTTP,还需要配置certificate source。Fabio并不像traefik那样可以自动去acme证书,它需要配置证书源,证书源可以是file / path / http / consul / vault。这个有空再说,访问一下它:
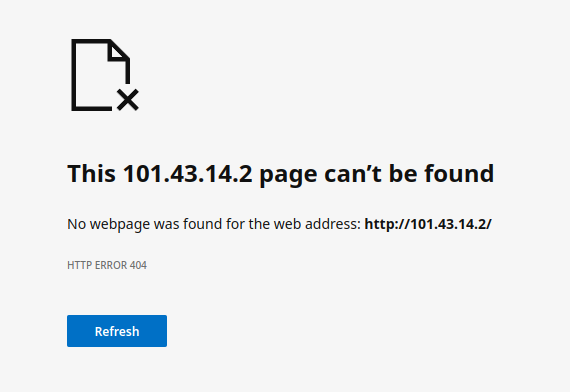
404了,而且是光突突的404,因为它也确实啥都没有,fabio也没有默认的404错误页面,只有status,没有body。咱们先来搞一个HTTP的后端服务:
job "test" {
datacenters = ["tencent-sh"]
type = "service"
group "test" {
count = 3
network {
port "http" {
to = 80
}
}
service {
port = "http"
tags = ["urlprefix-/"]
check {
type = "http"
path = "/"
interval = "10s"
timeout = "2s"
}
}
task "nginx" {
driver = "podman"
config {
image = "nginx:alpine"
ports = ["http"]
}
}
}
}
启动了nginx,实例数=3。tags=urlprefix-/是为了让fabio从consul里确定用来路由的方式,访问根目录,就路由到了nginx服务里,三个实例会自动选择,也就是实现了动态负载均衡。不过这里出现了个问题:
network里咱们设置的是to=80,在这个模式下,nomad会选择主机的一个随机端口,mapping到podman容器的80端口上,而由于防火墙的问题,consul是找不到lightinghouse节点上的服务的,于是健康检查是失败:
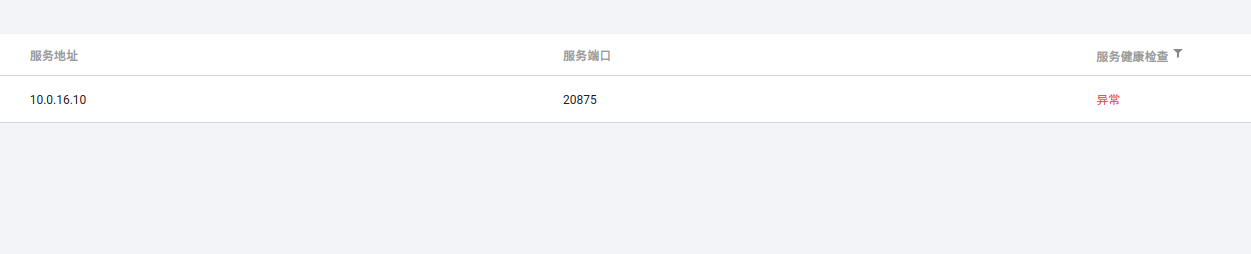
fabio也可能无法正确地代理到nginx上去。理想状况下,集群内应该有一张私有的虚拟网络,类似swarm的overlay network一样,由引擎提供的二层或三层实现互联,并在逻辑上忽略节点间的边界。这个是可以实现的,因为nomad支持CNI。
咱们暂时先指定一个静态的端口,在network中添加一条static:
network {
port "http" {
static = 8080
to = 80
}
}
配置8080端口的防火墙规则,重启test,可以看到consul确定了nginx的状态:

访问一下看看:
fabio正确路由到了nginx上去。
其实,并不需要一定要把容器的端口映射到主机上,bridge到引擎上即可,可是podman并不支持bridge network,可以改成docker。看来玩得花其实是给自己找了麻烦。
简单总结一下
Nomad相对k8s是要单纯一些的,它自身完成的东西并不多,这也就导致了它的外部依赖不少,想要玩得深入需要相当多的精神头,对于简单的项目部署来说,内耗还是要比swarm高一些的(参考上篇)。对于需要一些高级的可控性、企业级安全性和full-stack虚拟机,本地应用程序支持的场景,还是很可以的。
我在想,盒子要不要切回swarm去,实在不想写那么多hcl了。
暂时FIN一下吧,这是nomad非常非常初级的一个趟坑,还有像CNI、vault、consul connect等非常多的东西没有跑,也没有布满env。我并不确定会不会把它引入生产,即使它自称和k8s处于同一个生态面。
那么下一次,咱们来弄k8s吧。FIN了FIN了。